{kind=link}

Statistics is hard, often counterintuitive, and burdened with esoteric mathematical equations. Statistics classes can be boring and demanding; students might be tempted to call it “Sadistics.” Good statistics are essential to good research; unfortunately many scientists and even some statisticians are doing statistics wrong. Statistician Alex Reinhart has written a helpful book, Statistics Done Wrong: The Woefully Complete Guide, that every researcher and everyone who reads research would benefit from reading. The book contains a few graphs but is blissfully equation-free. It doesn’t teach how to calculate anything; it explains blunders in recent research and how to avoid them.
Inadequate education and self-deception
Most of us have little or no formal education in statistics and have picked up some knowledge in a haphazard fashion as we went along. Reinhart offers some discouraging facts. He says a doctor who takes one introductory statistics course would only be able to understand about a fifth of the articles in The New England Journal of Medicine. On a test of statistical methods commonly used in medicine, medical residents averaged less than 50% correct, medical school faculty averaged less than 75% correct, and even the experts who designed the study goofed: one question offered only a choice of four incorrect definitions.
There are plenty of examples of people deliberately lying with statistics, but that’s not what this book is about. It is about researchers who have fooled themselves by making errors they didn’t realize they were making. He cites Hanlon’s razor: “never attribute to malice that which is adequately explained by incompetence.” He says even conclusions based on properly done statistics can’t always be trusted, because it is trivially easy to “torture the data until it confesses.”
Misconceptions about the p value
A p value of less than .05 is considered statistically significant by convention. It represents the probability of getting the results they got if the null hypothesis is true (that there is no difference between the two groups). Steve Novella has written about problems with using p-values before. Reinhart warns:
Remember, a p value is not a measure of how right you are or how important a difference is. Instead, think of it as a measure of surprise [emphasis added]. If you assume your medication is ineffective and there is no reason other than luck for the two groups to differ, then the smaller the p value, the more surprising and lucky your results are – or your assumption is wrong, and the medication truly works.
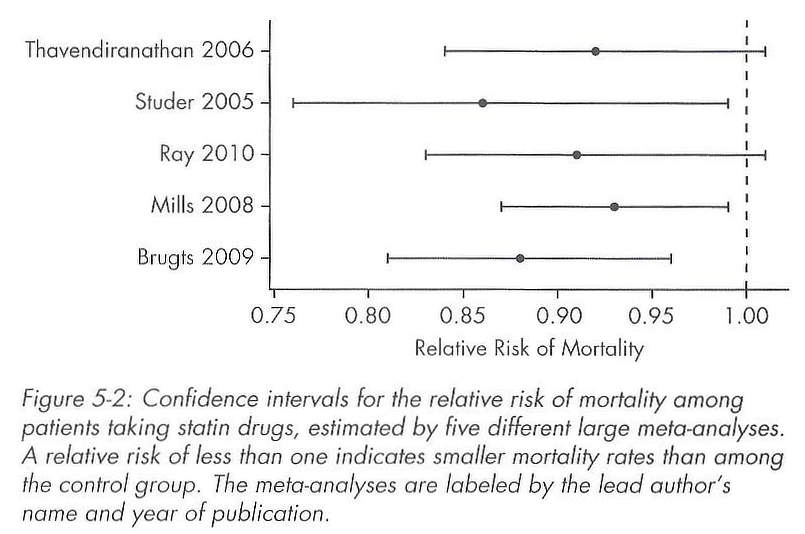
He explains confidence intervals and effect size and shows that they are much more meaningful than significance testing. As an example, five large meta-analyses set out to answer the question “do statins reduce mortality in patients with no history of cardiovascular disease?” Three meta-analyses answered yes, two answered no (based on finding or not finding significant differences at the p <0.05 level). People reading that would think the evidence was contradictory and inconclusive. But he presents a graph of confidence intervals showing that all five studies actually showed an effect of around 0.9: 10% fewer patients on statin drugs died. In the graph, only two of the studies’ confidence intervals overlapped the “no difference” line, and only by a very small amount. Looking at it this way, it is obvious that all of the meta-analyses actually showed that the answer was yes, statins do reduce mortality in patients with no history of cardiovascular disease.
Click to enlarge.
Common errors
Studies have shown that when women live together their menstrual cycles become synchronized. Reinhart eviscerates that flawed research and shows that menstrual synchrony is (still!) a myth. He mentions the infamous dead salmon MRI study and explains the errors that are commonly committed in brain imaging studies. He covers double-dipping in the data, the problem of multiple comparisons, truth inflation, the base rate fallacy, pseudoreplication, underpowered studies, circular analysis, regression to the mean, correlation is not causation, the loss of information when a continuous variable is arbitrarily dichotomized into two categories, regression models, missing data, degrees of freedom, methods to avoid bias, descriptions of methods that are too incomplete to allow replication by others, the need for open sharing of data, the file drawer and publication bias problems, the Reproducibility Project, reporting bias, poor compliance with registering clinical trials and reporting all their findings, and poor compliance with guidelines like CONSORT.
He shows why stopping rules must be defined in advance: it is tempting to stop the study at a point where the data favor your hypothesis, but further data collection might reverse the findings. He explains Simpson’s paradox, where an apparent trend in data is caused by a confounding variable and can be eliminated or even reversed by splitting the data into meaningful groups. He advocates not just double-blind, but triple-blind experiments, where the statisticians analyzing the data don’t know which group it came from. He shows the pitfalls of using computer programs to analyze statistics rather than consulting live statisticians. He reveals that errors are common in published studies: 38% of the papers in the journal Nature had typos and calculation errors in their p values, and reviews have found examples of mistakes like misclassified data, erroneous duplication of data, or even using the wrong dataset entirely.
When a new genetic test promised to tailor chemotherapy to the individual patient’s specific variant of cancer, analysis by statisticians showed the research to be such a mess that no conclusions could be drawn.
Possible solutions
He mentions several proposed statistical reforms (abandoning p values, switching to confidence intervals, switching to new Bayesian methods) but thinks they all have merits and doesn’t pick one to advocate. He calls for better statistics education with new evidence-based teaching methods aimed at identifying and overcoming students’ misconceptions and holes in their knowledge. He advocates reforms in scientific publishing. He gives specific guidelines for reading a scientific paper. In every chapter, he points out common errors and then gives concrete advice about how researchers can avoid them.
An excellent book
This book is well written, short (129 pages), enjoyable to read, and easy to understand. It is well-organized, divided conveniently into short chapters, and is enhanced by the examples of research done wrong that illustrate each of its points. It covers the subject thoroughly yet concisely, and provides copious references for readers who want to know more. Rather than a guide to statistics, it is really more of a guide to critical thinking about pitfalls in the use of statistics. I highly recommend it. Whether you are interested in research or statistics, want to know what to look for when reading a research paper, or just want to improve your critical thinking skills, you will find it of value. Even if you are an expert in statistics, you might think it deserves a place on your bookshelf.