
Last December, Scott Gavura wrote a nice piece at SBM, presenting the work of a short paper published in JAMA Internal Medicine in which the authors presented how AI and Large Language Models (LLMs) like ChatGPT can be manipulated to supercharge health misinformation and spread fake news in social media, calling for the need of regulatory frameworks and human monitoring by health professionals.
Although the threat of using Large Language Models (LLMs) for misinformation, disinformation, and malinformation (MDM) in science is indeed real, the proposed solutions involving regulatory frameworks and human-based countermeasures seem subpar compared to the level of threat we face.
Fighting fire with fire
If we have learned anything from the Age of the Internet, it is that cyber threats have been most effectively challenged and countered using the same cyber tools for defense.
Despite the introduction of numerous regulatory frameworks and legal tools over the decades against cyber-deception, our electronic history is replete with success stories where an attacking tool was repurposed as a defensive one, including the hacker wars of the ‘90s, where government agencies employed ex-hackers to defend their systems or identify weaknesses, to the ingenious defense mechanism invented to protect email inboxes from spam: the Junk Folder.
It’s only logical
Similarly, in the context of AI-driven MDM attacks on science, utilizing LLMs and related AI models as tools against MDM is logical. I mean, if these tools are far more efficient at producing fake information than humans, then only AI tools can help us defend effectively against it, right?
This is best articulated in a study from the Pennsylvania State University by Lucas et al (2023), where they comment:
“To combat this emerging risk of LLMs, we propose a novel “Fighting Fire with Fire” (F3) strategy that harnesses modern LLMs’ generative and emergent reasoning capabilities to counter human-written and LLM-generated disinformation.”
That’s spot on, although the authors’ suggestion is not exactly novel. More than a year ago, when LLMs started getting more publicity, Edward Tian, a 22-year-old student at Princeton University immersed in studying GPT-3 — which is the previous version of ChatGPT — developed an app to identify content created by AI, in just three days. His app employed the machine learning model of ChatGPT in reverse, examining texts for signs characteristic of AI-produced material.
However, a small early study on Tian’s tool reported that the app had a low false-positive (classifying a human-written text as machine-generated) and a high false-negative rate (classifying a machine-generated text as human-written). No one expected it would be easy. But it was a start.
Countering LLM-generated Fake News
Numerous studies have examined the ‘F3 strategy’ of employing LLMs to counteract LLM-generated fake news. Anamaria Todor and Marcel Castro, Principal and Senior Solutions Analysts at Amazon Web Services, respectively, have investigated the potential of LLMs in detecting fake news. They argue that LLMs and AI-related tools are adequately advanced for this task, especially when employing specific prompt techniques like the Chain-of-Thought and ReAct patterns, along with information retrieval tools.
Looking for patterns
For those less familiar with ChatGPT and similar LLMs, ‘patterns’ refer to the various ways a user formulates commands or instructions to the LLM, aiming to improve the likelihood of obtaining a desired result. Abusers often exploit these patterns to craft misinformation that is as convincing as possible. Todor and Castro developed a LangChain application which, upon receiving a news item, can analyze its language pattern to determine whether the article is authentic or fabricated.
And this is very interesting. A number of studies have confirmed that language plays a crucial role in detecting AI-driven MDM. It seems that the way language is used by these AI models has some distinct differences from the way humans use it, which can be exploited and help us identify it. Imane Khaouja, an NLP Researcher and Data Scientist who tested an AI model called CT-BERT, wrote in a recent blog post about the way that these AI tools can use language as a marker for detecting misinformation:
“Upon analyzing (..), it becomes apparent that real tweets tend to use scientific and factual language. (..) Real tweets are characterized by a reliance on objective information, logical reasoning, and a commitment to accuracy. In contrast (..) fake tweets predominantly rely on emotional and sensationalist language. These articles often contain exaggerated claims, lack factual evidence, and employ emotional and fearmongering tactics to manipulate readers’ emotions. The use of such language and techniques aims to provoke strong emotional responses and capture the attention of the audience, potentially leading to increased engagement and sharing of the content.”
“COVID-Twitter-BERT”
CT-BERT, which stands for “COVID-Twitter-BERT”, is an AI-model developed by a Swiss-Spanish search collaboration. The model is pre-trained on a large corpus of COVID-19 related Twitter posts and can be utilized for various natural language processing tasks such as classification, question-answering, and chatbots.
The authors did not design CT-BERT to fight misinformation on COVID-19, but a Russian research team used CT-BERT to win the “COVID-19 Fake News Detection Challenge” at the 2021 conference of the Association for the Advancement of Artificial Intelligence (AAA 2021). In that competition, 166 research teams from around the world used their AI models against a set of twitter posts that presented misinformation about COVID-19, and their performance was scored. The CT-BERT model of the winning team achieved a weighted F1-score of 98.69 on the test set, winning the first place in that competition.
Human-written disinformation vs LLM-generated variants
Going back to the study by Lucas et al., their findings regarding the role of language were particularly intriguing. First, they observed that ‘LLMs struggle more to detect human-written disinformation compared to LLM-generated variants.’ This outcome is somewhat anticipated, considering the differences in language usage by the two creators, humans and LLMs.
Second, they noted that LLMs were more adept at identifying misinformation in lengthy news articles than in short social media posts. This can be attributed to the limited language in short articles, making them more challenging to classify successfully. However, Lucas et al. reported promising results in their model’s ability to detect misinformation within a vast array of online content. They concluded that ‘assessing detection and disinformation mitigation will be critical as LLMs continue to advance.
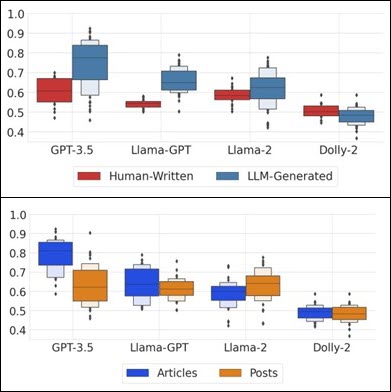
Accuracy (F1) scores on detecting LLM-generated disinformation and human-authored disinformation (above) and on evaluating the efficacy of different LLMs detecting short social posts (below). Taken from Lucas et al.
The need for a more robust and synchronized strategy
Despite a large number of studies, similar to Lucas et al, that examine different ways we can use AI-models and LLMs against fake information, especially in the context of science and health science, the field is still in its infancy. A more robust and synchronized strategy needs to be implemented using various methodologies.
In a recent (unpublished) work by Canyu Chen and Kai Shu from the Illinois Institute of Technology, the authors reviewed cases and studies where LLMs and related AI tools can and have been used against misinformation. They categorize them in three main ways:
- Misinformation Detection – using algorithmic-based AI tools to detect human-produced LLM-produced misinformation (example),
- Misinformation Intervention – taking advantage of LLMs’ fast-generating capacity to produce solid counter-arguments and reasoning against presented MDM, to improve the convincingness and persuasive power of the debunking responses (example) and
- Misinformation Attribution – using AI tools to identify the author(s) of MDMs, combating misinformation by tracing the origin of propaganda or conspiracy theories and hold the publishers or source accountable.
Timing is everything
One big limitation of using LLMs against MDM attacks is the timing constraints existing in checking factual information. The knowledge contained in most LLMs is not up-to-date (i.e. the knowledge cutoff date for GPT-4 is April 2023) so it’s difficult to use LLMs to check information for facts in dates after the model’s cutoff date.
To bypass this hurdle, we need to introduce external help, where humans or machines can help LLMs by introducing newer data in their learning prior to fact-checking. For example, Cheung & Lam combined the retrieved knowledge from a search engine and the reasoning ability of an LLM to predict the veracity of various claims (unpublished). In another study, Chern et al. proposed a fact-checking framework integrated with multiple tools, such as Google Search and Google Scholar) to detect the factual errors of texts generated by LLMs (unpublished).
All hands on deck
In this early stage of LLM development, one thing that is universally clear from the related literature when it comes to combat MDM using LLMs and related AI tools, is that there is still a long way to go, but it seems the right way to go. Developing MDM is still easier than combating MDM, using the same tools. Which is kinda natural, if you consider that LLMs and ChatGPT entered our lives only about a year ago or so.
Nevertheless, using AI-models to detect and publicize deceptors might not be enough. All hands should be on deck. That means using every human tool at our disposal to fight MDMs — from placing regulatory frameworks on LLM development and use, to forcing developers to include fail-safe mechanisms against misuse into their models.
Three-stage strategy
Canyu Chen and Kai Shu discussed this in their recent work, presented at the 37th Conference on Neural Information Processing Systems (NeurIPS 2023). The authors proposed a three-stage strategy for tackling LLM-produce misinformation:
- At the training stage, by removing nonfactual content from the LLMs training data,
- At the usage stage, by introducing safety valves such as prompt filtering against using LLMs to produce misinformation, and
- At the influence stage, by using LLMs for misinformation detection, intervention and attribution, as described above.
This synchronized and systematic action could be a more efficient and optimum strategy to battle AI-driven MDM.
Humans and AI united
The battle against AI-driven science and health misinformation demands a strategic blend of AI tools and rigorous regulatory measures. While leveraging LLMs and related AI tools for detection and intervention is promising, it’s still imperative to couple these technologies with ethical guidelines and human expertise. The path forward is challenging but it offers a unique opportunity for synergistic solutions, uniting AI’s computational prowess with human judgment to safeguard scientific discourse. This dual approach is crucial in navigating the complexities of misinformation in the rapidly evolving AI landscape.

{kind=link}