{kind=link}
One of the most contentious questions that come up in science-based medicine that we discuss on this blog is the issue of screening asymptomatic individuals for disease. The most common conditions screened for that we, at least, have discussed on this blog are cancers (e.g., mammography for breast cancer, prostate-specific antigen screening for prostate cancer, ultrasound screening for thyroid cancer), but screening goes beyond just cancer. In cancer, screening is a particularly-contentious issue. For example, by simply questioning whether mammography saves as many lives lost to breast cancer as advocates claim, one can find oneself coming under fire from some very powerful advocates of screening who view any questioning of mammography as an attempt to deny “life-saving” screening to women. That’s why I was very interested when I saw a blog post on The Gupta Guide that pointed me to a new systematic review by John Ioannidis and colleagues examining the value of screening as a general phenomenon, entitled “Does screening for disease save lives in asymptomatic adults? Systematic review of meta-analyses and randomized trials.”
Before I get into the study, let’s first review some of the key concepts behind screening asymptomatic individuals for disease. (If you’re familiar with these concepts, you can skip to the next section.) The act of screening for disease is based on a concept that makes intuitive sense to most people, including physicians, but might not be correct for many diseases. That concept is that early intervention is more likely to successfully prevent complications and death than later intervention. This concept is particularly strong in cancer, for obvious reasons. Compare, for example, a stage I breast cancer (less than 2 cm in diameter, no involvement of the lymph nodes under the arm, known as axillary lymph nodes) with a stage III cancer (e.g., a tumor measuring greater than 5 cm and/or having lots of axillary lymph nodes involved). Five year survival is much higher for treated stage I than for treated stage III, and, depending on the molecular characteristics, the stage I cancer might not even require chemotherapy and can be treated with breast conserving surgery (“lumpectomy” or partial mastectomy) far more frequently than the stage III cancer. So it seems intuitively true that it would be better to catch a breast cancer when it’s stage I rather than when it’s stage III.
Unfortunately, that’s not necessarily the case. The reasons are phenomena known as lead time bias, length bias, and overdiagnosis. Lead time bias has been explained multiple times (e.g., here and here), but perhaps the best explanation for a lay public I’ve ever found of lead time bias (although he doesn’t call it that) involves a hypothetical example of cancer of the thumb by Aaron Carroll. Given that cancer survival is measured from the time of diagnosis, if a tumor is diagnosed at an earlier time in its course through the use of a new advanced-screening detection test, the patient’s survival will appear to be longer, even if earlier detection has no real effect on the overall length of survival, as illustrated below:
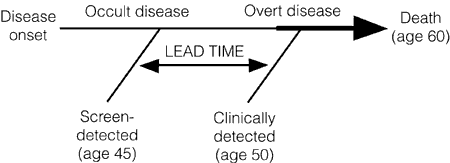
Lead time bias, in other words, can give the appearance of longer survival even when treatment has no effect whatsoever on the progress of the disease. Patients are simply diagnosed earlier in the disease time course and only appear to live longer when in reality they simply carry the diagnosis screened for longer.
The second concept is length bias. In general, we can’t continually screen for disease so an interval has to be chosen. This introduces a bias. Length bias refers to comparisons that are not adjusted for rate of progression of the disease. The probability of detecting a cancer before it becomes clinically detectable is directly proportional to the length of its preclinical phase, which is inversely proportional to its rate of progression. In other words, slower-progressing tumors have a longer preclinical phase and a better chance of being detected by a screening test before reaching clinical detectability, leading to the disproportionate identification of slowly-progressing tumors by screening with newer, more sensitive tests, with the faster-growing tumors becoming symptomatic “between screenings.” Thus, survival due to the early detection of cancer is a complicated issue.
Finally, there is overdiagnosis. This is a term that refers to disease detected that would likely never progress within the timeframe of the patient’s remaining lifetime to cause a problem. For cancer (for example) it seems completely counterintuitive that there could be overdiagnosis, but there is. As we have learned over the last several years, cancer overdiagnosis is definitely an issue, particularly for the prostate and breast, with perhaps as high as one in three mammography-detected breast cancers in asymptomatic women being overdiagnosed. Basically, this chart illustrates the concept well:
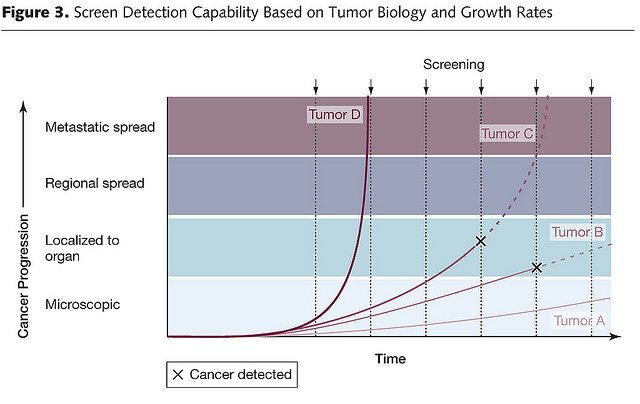
In this chart, which shows growth rates of four hypothetical tumors (A, B, C, and D), tumor D would not be detected because it was growing too fast, while tumor A is growing so slowly that it would likely be overdiagnosed when it reaches the threshold of detectability. Only tumors B and C could potentially benefit from being detected while still confined to the organ. This sort of graph explains why ever-more-sensitive tests that detect disease earlier and earlier have the potential to result in more overdiagnosis.
Finally, overdiagnosis almost inevitably results in overtreatment. Once physicians have detected a disease, be it a cancer, an asymptomatic abdominal aortic aneurysm, or whatever, the onus is on them to treat it.
Now, on to Ioannidis’ review.
Screening, huh! What is it good for? (Probably not absolutely nothing.)
In Ioannidis’ systematic review of meta-analyses and randomized clinical trials, he and coauthors Nazmu and Julianne Saquib take a different approach than I’ve usually seen. Most such systematic reviews and meta-analyses examine screening for only one disease, while this one examines screening for a number of diseases. Also, the key questions to be asked included:
- Does the screening test result in a decrease in mortality due to the disease being screened for (known as disease-specific mortality)?
- Does the screening test result in a decrease in mortality due to all causes?
The background is explained right in the introduction:
Screening for disease is a key component of modern health care. The rationale is simple and attractive—to detect diseases early in asymptomatic individuals and to treat them in order to reduce morbidity, mortality and the associated costs. However, the role of screening often comes into question. Some high-profile controversies have appeared lately in this regard. For example, for breast cancer, the United States Preventive Services Task Force (USPSTF) currently recommends against routine mammographic screening for women aged 40–49 years after retracting its previous recommendation in favour of mammography, as the data failed to show that benefit outweighed harm. The decision against screening drew sharp criticism from various interest groups including patients who overestimate the benefit of screening. Similarly, USPSTF now recommends against screening for prostate cancer in healthy men because harms from prostate specific antigen (PSA) screening exceed the benefit, trials do not show improvement in long-term survival and screening carries a high risk of over-diagnosis with adverse consequences. Again, heated debates have been generated around this change of recommendation, both in the scientific and the popular press.
Some screening tests were entrenched in clinical and public health practice before randomized controlled trials (RCTs) became widely used. As the screening agenda encompasses a large number of tests, and new ones are continuously proposed, it is useful to reassess the evidence supporting their use. Our research question is whether recommended screening tests, among asymptomatic adults, have evidence from RCTs on mortality for diseases where death is a common outcome. In particular, is there evidence of mortality reduction, either disease-specific or all-cause, from screening? To this end, we have compiled and examined systematically the evidence from individual RCTs and meta-analyses thereof for screening tests that have been proposed for detecting major diseases in adults who have no symptoms.
None of this should come as a surprise to regular readers of this blog. But how to answer such a large question regarding the potential benefits and harms of routine screening? Basically, what Saquib et al. did was search the United States Preventive Services Task Force (USPSTF), Cochrane Database of Systematic Reviews, and PubMed, looking for recommendation status, category of evidence, and availability of randomized clinical trials (RCTs) on mortality for screening tests for diseases in asymptomatic adults (excluding pregnant women and children) from the USPSTF. They then identified the relevant RCTs. The chart below summarizes the existing state of evidence identified in the systematic review:
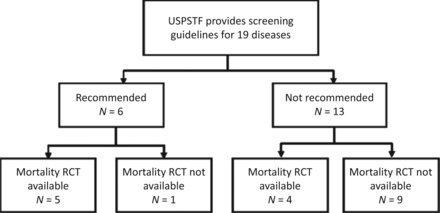
You can examine the data in Tables 1 and 2 yourselves, in which Saquib et al. examined meta-analyses and individual trials for 39 screening tests for 19 diseases in asymptomatic adults. What is very clear is that there is little strong RCT evidence of benefit for disease-specific mortality for many of these modalities. Indeed, The Gupta Guide notes that, for the six diseases/conditions for which the USPSTF recommends screening, only five of them have strong RCT evidence for a reduction in disease-specific mortality: breast, cervical, and colorectal cancer; abdominal aortic aneurysm (AAA); and type 2 diabetes. There were no randomized trials for screening for hypertension.
Basically, in the individual RCTs examined, the risk of disease-specific mortality was reduced in 16 out of 54 tests (30%), while all-cause mortality was reportedly reduced in 4 of 36 RCTs (11%). Examples of tests for which disease-specific mortality was reduced included ultrasound for AAA (42%-73% risk reduction), mammography for breast cancer (0% to 27% risk reduction), and screening for cervical cancer (11% to 48% risk reduction). For the meta-analyses examined, the risk of disease-specific mortality was reduced in analyses of four of eleven tests, but none for all-cause mortality. Examples of screening tests for which disease-specific mortality was reduced included ultrasound for AAA (again, risk reduction of 45%) and mammography (10% to 25% risk reduction). However, none of the meta-analyses showed an all-cause mortality benefit, while all-cause mortality was reduced only by 3%-13% in the RCTs examined. Basically, the findings were disappointing.
The authors note several possible reasons for their findings:
There are many potential underlying reasons for the overall poor performance of screening in reducing mortality: the screening test may lack sufficient sensitivity and specificity to capture the disease early in its process; there are no markedly effective treatment options for the disease; treatments are available but the risk-benefit ratio of the whole screening and treatment process is unfavourable; or competing causes of death do not allow us to see a net benefit. Often, these reasons may coexist. Whether screening saves lives can only be reliably proven with RCTs. However, even for newly proposed tests, we suspect that their adoption in practice may evade RCT testing. A very large number of tests continuously become available due to technological advancement. One may be tempted to claim a survival benefit of screening based on observational cohorts showing improved survival rates, but these are prone to lead-time and other types of bias. Even RCTs can be biased sometimes, as has been discussed and hotly debated in the controversy over mammography.
The authors also note that they did not examine evidence from other trial designs, such as cohort and case-control studies, which could be a potential weakness. Of course, they also make the obvious defense that these studies are generally less robust than RCTs and more prone to biases. The other concession they make is that it can be incredibly difficult to detect reductions in all-cause mortality for the simple reason that the disease being screened for almost always represents only a fraction of causes of death. This means that even a large drop in mortality due to screening for one disease would, even under ideal conditions, result in only a much smaller drop in all-cause mortality. Such a drop is very difficult to detect in an RCT because of the enormous numbers involved.
What is the proper metric to evaluate a screening test?
This point leads us naturally into the discussions of this study. Presented with the study were commentaries by Peter C. Gøtzsche of the Nordic Cochrane Center and Paul Taylor of the Institute of Health Informatics, University College London, entitled “Screening: a seductive paradigm that has generally failed us” and “Tempering expectations of screening: what is the most authoritative advice we can give, given the data that we have?“, respectively. Basically, Gøtzsche, as one might expect based on his previous criticisms of mammography, argues that total mortality should be the primary outcome in screening trials of mortality and that the main focus of screening trials should be to “quantify the harm.” Taylor, on the other hand, argues that in reality the results of Saquib et al. are not so bad, given that 30% of trials showed a disease-specific benefit and even proponents of screening would expect more trials to fail than not. He also points out the difficulties of using all-cause mortality as the primary outcome.
First, let’s see what Gøtzsche argues:
Screening proponents often say that disease-specific mortality is the right outcome, arguing that in order to show an effect on total mortality, trials would become unrealistically large. I believe this argument is invalid, for both scientific and ethical reasons. We do randomized trials in order to avoid bias, and our primary outcome should therefore not be a biased one. Drug interventions are usually more common in a screened group, and they tend to increase mortality for a variety of non-disease related reasons.
While it is true that overtreatment could potentially increase mortality for reasons other than disease, I believe that Gøtzsche is holding screening to an unrealistically high standard. Using his standard, it would be pointless to screen for virtually anything. Why? I like to use breast cancer as an example to illustrate the difficulties of using all-cause mortality as the be-all and end-all for screening. I know the numbers are rough and the analysis simplistic, but the magnitude is illustrative and close enough to give you an idea of the issues involved. This argument takes the form of a simple thought experiment. Consider first that approximately 40,000 women a year die of breast cancer in the US. However, there are approximately 2.5 million total deaths per year, which means that approximately 1.25 million women die every year (estimated to be 1.26 million in 2011). Thus, breast cancer is the cause of approximately 3.2% of female deaths every year. Consequently, if we could prevent 100% of breast cancer deaths (an unrealistic goal), at most we would expect to see a reduction in all-cause mortality of 3.2%.
Aha! I hear some of you saying. You’re counting all female deaths, even those of children, where breast cancer is so incredibly unlikely to be a cause that these deaths should be discounted. Fair enough. Let’s look at women under the age of 40 (the age at which screening begins, making this the group of women for whom screening is instituted with the goal of preventing death from breast cancer). If we subtract the 63,125 deaths that occur per year in women before the age of 40, we’re left with 1,196,875 deaths, which leads us to estimate the number of breast cancer deaths as 3.3% of total deaths of women aged 40 and above—not much different. Of course, some women do die before age 40 of breast cancer. In the US, approximately 1,160 women under 40 die every year of the disease. That brings the proportion of deaths in women over the age of 40 due to breast cancer back down to 3.2%
So let’s say mammography, as an upper estimate, results in a 27% decrease in breast cancer-specific mortality in women over 40. Under ideal circumstances, that would translate into a less than 0.9% decrease in all-cause mortality. The numbers of subjects and years of follow-up in an RCT needed to detect such a small number would be prohibitively expensive. Obviously, for diseases that cause a higher percentage of overall deaths, it will be easier to detect a reduction in all-cause mortality, but for most diseases it’s very difficult indeed to tease out an all-cause mortality except using clinical trials so huge as to be impractical. Of course, this cuts both ways. If you see a decrease in overall mortality due to screening reported that’s bigger than the proportion of deaths expected to be caused by the disease in the age group studied, then something odd is going on, possibly bias.
In any case, I realize my “back of the envelope” calculations are simplistic. They don’t, for example, rigorously consider the trial period and how many deaths would be expected during, for example, one, two, three, or four decades or adjust for age other than in the crudest manner. My point in having done them isn’t to give exact numbers, but rather to illustrate that the question of whether to use disease-specific mortality or all-cause mortality as a primary endpoint in trials screening for diseases that can result in death is not as straightforward a question as Prof. Gøtzsche argues, although he is correct to note that screening is not without harm and that the harms of screening for some diseases can outweigh the benefits. In an ideal world, he’d be correct about all-cause mortality as an endpoint, too, but our world is not ideal, and detecting such small differences in all-cause mortality is often beyond what is feasible and our resources can support.
Taylor, in his response, also notes another confounder:
But there’s the rub. If breast cancer deaths are reduced, but all-cause mortality is unaffected, is this because detecting the latter requires that more statistical power be deployed? Or is it, as Gøtzsche has suggested, because the harms of screening increase deaths from other causes? The most serious cause of harm is overdiagnosis. The independent UK panel took the view that the best estimate of overdiagnosis could be provided by comparing the rates of cancer detection in the screened and the unscreened groups of randomized controlled trials. The problem is that when most trials ended, screening was offered to the women in the control groups, creating overdiagnosis in the follow-up period. The panel therefore restricted their attention to three trials in which no screening was offered to the control group during follow-up. This is a very limited set of data. Saquib, Saquib and Ioannidis ignore the question of harms presumably because there simply are not enough RCT data to review.
In other words, even in these studies, it’s hard to tease out the sorts of data we are interested in so many decades later. Gøtzsche concludes, without presenting concrete evidence to that effect, that the harms of screening negate the benefits, thus resulting in no detectable decline in all-cause mortality. Advocates assume, without proving, that it is a matter of lack of statistical power, as I discussed above, and that bigger trials with more power would detect all-cause mortality decreases. Chances are, it’s both, the relative proportion of each contribution varying according to the specific disease and screening test under study. One thing is certain, though. All screening results in some degree of overdiagnosis. As I’ve said time and time again, whenever you screen for a condition, you will always find a lot more of it. Always. Just consider the 16-fold increase in the incidence of ductal carcinoma in situ since the mammography era began.
There is no doubt in my mind that screening has, in general, been oversold, represented in some cases as a magic bullet that will save far more lives than it actually can. It’s been a relatively recent realization on the part of physicians that overdiagnosis is a real problem because it leads to overtreatment, which can cause harm. Also, in the case of cancer, improvements in treatment could well be blunting any benefits observed due to screening, as Taylor noted in his commentary. On the other hand, that screening has not lived up to its promise does not mean it is useless, as some critics have charged. It is not unreasonable, as Taylor described, to value other outcomes besides mortality. Unfortunately, we’re in the messy and contentious process of trying to determine which screening tests do save lives. As Saquib et al put it:
We argue that for diseases where short- and medium-term mortality are a relatively common outcomes, RCT should be the default evaluation tool and disease-specific and all-cause mortality should be routinely considered as main outcomes. Our overview suggests that even then, all-cause mortality may hardly ever be improved. One may argue that a reduction in disease-specific mortality may sometimes be beneficial even in the absence of a reduction in all-cause mortality. Such an inference would have to consider the relative perception of different types of death by patients (e.g. death by cancer vs death by other cause), and it may entail also some subjectivity. For diseases where mortality outcomes are potentially important but only in the very long term, one has to consider whether the use of other, intermediate outcomes and/or other quasi-experimental designs that may be performed relatively quickly with very large sample sizes (e.g. before and after the introduction of a test) are meaningful alternatives to very long-term RCTs or may add more bias and confusion in a field that has already seen many hot debates. Screening may still be highly effective (and thus justifiable) for a variety of other clinical outcomes, besides mortality. However, our overview suggests that expectations of major benefits in mortality from screening need to be cautiously tempered.
In other words, the science of screening is messy, and we need to be careful not to be too optimistic. Personally, I tend to agree with Taylor, that better risk stratification will be necessary. Screening tends to benefit most populations at high risk for the disease being screened for. Such stratification could allow for—dare I say it?—personalized screening based on individual risk factors.
One wonders how much of that sort of research will be funded in President Obama’s Precision Medicine Initiative, should it be funded. I might have to look into that for a future topic.