
{kind=link}
As repetitive as I have been with respect to this, there is nothing new under the sun when it comes to antivaccine myths, misinformation, and disinformation, and that applies to COVID-19 vaccines. If public health officials and messengers had paid more attention to the tactics and tropes of the antivaccine movement, including its central conspiracy theory, maybe they would have been more prepared for the onslaught of antivaccine misinformation that was unleashed as the mRNA COVID-19 vaccines were undergoing clinical trials and when they were finally initially approved under an emergency use authorization (EUA) near the end of 2020. They didn’t, and here we are, which is why, having seen it before multiple times last year, I’m faced with the return of the revenge of the antivaccine lie that mRNA-based COVID-19 vaccines “permanently alter your DNA” (they don’t, nor do they “hack the software of life“, nor are they really “gene therapy“) this time from Jessica Rose, who is affiliated with James Lyons-Weiler‘s antivaccine “institute” with the humble name of Institute for Pure and Applied Knowledge (IPAK). Unfortunately, Saturday I saw this zombie lie resurrected yet again in the form of an article on Substack (where the cranks who’ve been banned from Twitter, Facebook, YouTube, etc. all go) by Rose titled “It does incorporate into human DNA. And it’s probably messing up embryogenesis“, subtitled, These injectable convid-1984 products are perfect bioweapons—either by design or accident. Who cares which. The outcome is the same.
Once more unto the breach, I guess! I suppose that while I’m here I should link to the two studies published last week and cited by Rose in her Substack to support her nonsensical claims that (1) the finding of a short nucleotide sequence in the spike protein mRNA sequence used in the Moderna vaccine is slam dunk evidence that SARS-CoV-2 was “engineered” and that the “lab leak” hypothesis for SARS-CoV-2 is true and (2) that SARS-CoV-2 “permanently alters your DNA” by being reverse transcribed and integrated into the DNA in its recipient’s chromosomes. Let’s just say that neither Rose’s cited study from Lund University in Sweden about the supposed reverse transcription of the Pfizer/BioNTech mRNA-based vaccine into the DNA of human cells nor the study by Ambati et al about MSH3 homology support these hysterical claims.
Before I proceed, let’s just reiterate that the idea that vaccines can “permanently alter your DNA” is not new to mRNA-based COVID-19 vaccines, although the nature of these vaccines makes that claim easier for antivaxxers to sell as plausible to those not familiar with molecular biology. Indeed, if you really look carefully at it, the claim that vaccines somehow changes your DNA actually dates back to before scientists even understood DNA as the basis of heredity, as illustrated, for example, by this famous “Cow-Pock” cartoon from 1802 by satirist James Gillray about smallpox vaccine:

Even a few years after Edward Jenner introduced the smallpox vaccine, the idea that vaccines somehow permanently alter humans had begun. (Source: Wikipedia and the Library of Congress, Prints & Photographs Division, LC-USZC4-3147, color film copy transparency.)
Savvy readers will notice how much a meme that was going around a year or so ago about the mRNA vaccines is very much of a piece with this 220-year-old cartoon:

How is this any different from 19th century antivax cartoons?
Similarly, the idea that an “engineered virus,” whether intentionally released or accidentally “leaked” from a laboratory, caused the pandemic is the same conspiracy theory that arises during every epidemic and pandemic, from various influenza pandemics to AIDS to Ebola. Of course, in the age of sophisticated molecular biology and genetics, antivaxxers can always find a special case that seems to show that the impossible is actually possible, and Jessica Rose is just continuing in this antivax tradition of misusing science, as I’ll try to explain.
The “central dogma” of molecular biology, or: Why mRNA vaccines do not “alter” your DNA
Before I discuss the two studies and the claims being made about them not just by Jessica Rose but by a number of antivaxxers, let’s take a look at some basic biology and molecular biology, so that you understand why her claims are so beyond the ken. I realize that I’ve done this before, but it’s been a while; so instead of just including links to my previous discussions, I’ll include a brief explanation of something out of Biology 101, so that we’re all on the same page. If you know all of this, you can probably skip to the next section. If not, let’s proceed.
mRNA vaccines rely on the “central dogma” of molecular biology. As I’ve said many times before, I’ve always hated the use of the word “dogma” associated with science, but no less a luminary than Francis Crick first stated it in 1958, and it has been restated over the years in various ways. Perhaps my favorite version of the central dogma was succinctly stated by Marshall Nirenberg in 1958 and has since been commonly paraphrased to say, “DNA makes RNA makes protein”, which about summed up all of molecular biology in five words. (Why I used the past tense in a moment.) In any event, for purposes of understanding the very basics of RNA vaccines, this is the main sequence that you need to understand.
It’s true, of course, that DNA replicates from a DNA template and results in a double-stranded molecule that is very stable, as it has complementary sequences that tightly bind to each other in a sequence-specific fashion. This DNA template is unwound by enzymes that use the template to make RNA, which is single-stranded. That RNA—when used to code for a protein called a “messenger RNA” or “mRNA”—is then used by a ribosome to make protein out of amino acids. Again, to put it simply, each nucleotide equals one letter of the code; each three-nucleotide sequence (codon) equals one “word” that translates to an amino acid. Given that there are four nucleotides, there are 64 possible codons. Since there are only 20 amino acids, that means that most amino acids are encoded by more than one combination of nucleotides or more than one codon; i.e., the genetic code is redundant. Of course, as is the case with nearly everything in biology, it’s more complicated than that, as these diagrams show:
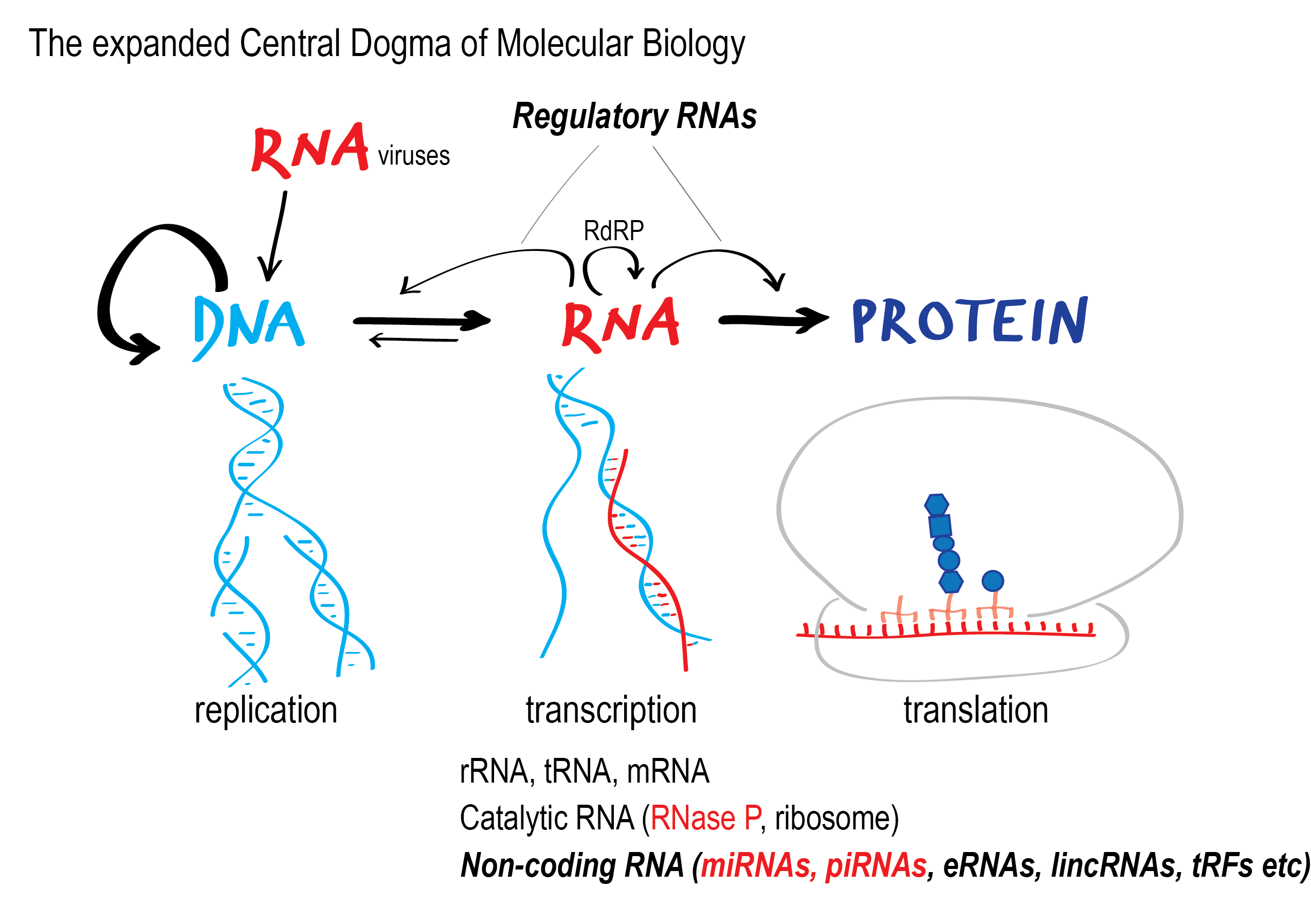
The “Central Dogma of Molecular Biology.” Information flows from DNA to RNA and then is used to make protein.
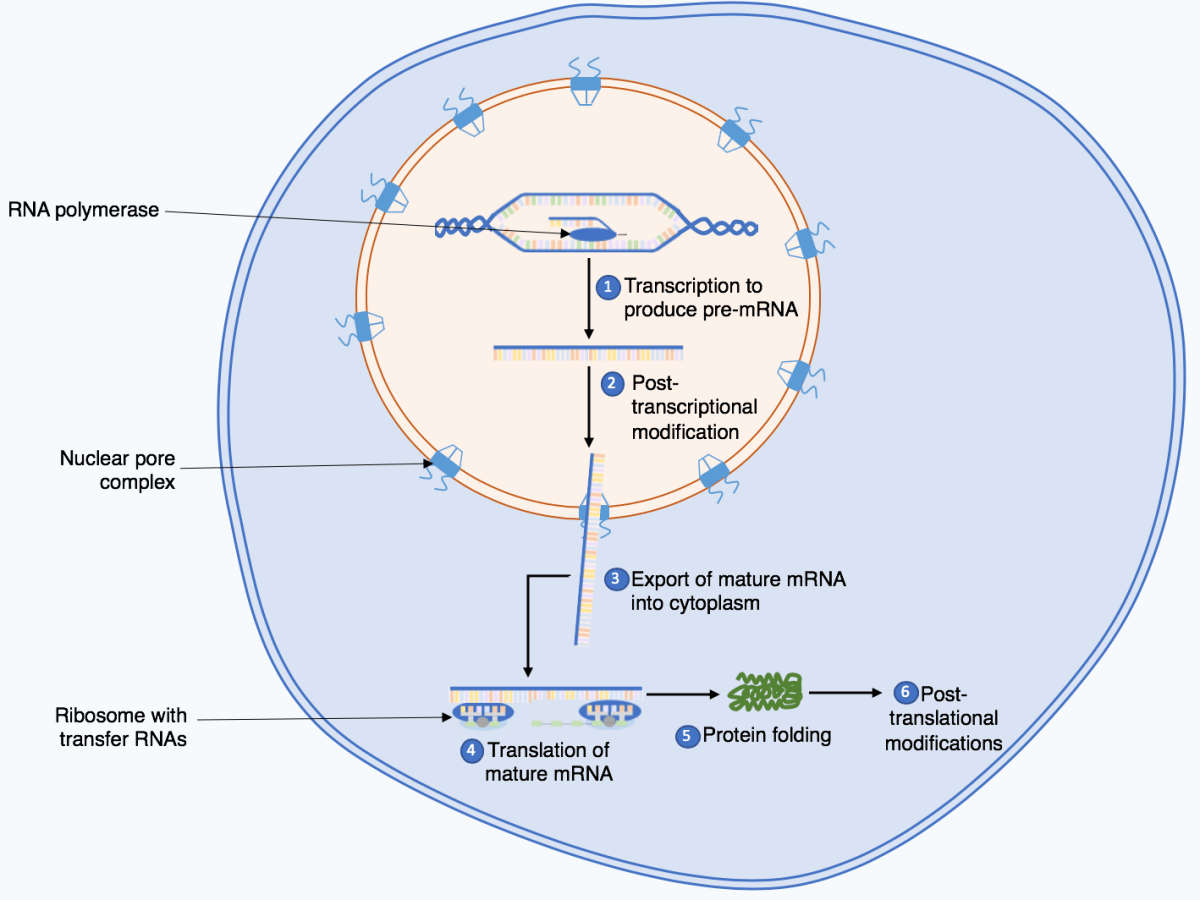
Information flows from DNA in the nucleus, to RNA, which is transported into the cytoplasm and used as a template to make protein.
There are more complications to this seemingly simple scheme, of course. mRNA doesn’t always start out fully formed. Often it’s made as a longer precursor molecule, parts of which are spliced out by enzymes, to produce the final mRNA sequence before the mRNA molecule is used as a template to make protein. There are also other complexities that go beyond the central dogma, such as retroviruses, which make DNA using RNA templates, and microRNA, which can regulate gene expression by binding to specific sequences on mRNAs and blocking transcription and/or inducing the breakdown of the mRNA molecule, for instance. You don’t really need to know the gory details of these processes or others, though, except retroviruses, whose ability to “reverse the flow of information”, so to speak, by transcribing DNA off of an RNA template using an enzyme known as reverse transcriptase will be very relevant to the discussion of the Swedish paper. HIV is the retrovirus that is the most well-known because of its ability to cause AIDS.
Exceptions aside, RNA vaccines consist mainly of, well, RNA. One problem with RNA vaccines is that RNA is an inherently unstable molecule. It is, after all, a messenger. It doesn’t need to persist any longer than the message needs to be made. In aqueous solution, RNA molecules rapidly degrade. Indeed, the instability of RNA is why public health experts have been concerned about distributing RNA vaccines. Both Pfizer/BioNTech and Moderna adopted a similar strategy in designing their mRNA to encode the SARS-CoV-2 spike protein with stabilizing mutations added to lock this surface protein into a form easily recognizable to the immune system and therefore make it a better antigen. Pfizer and Moderna also used modified nucleosides (the RNA equivalent to DNA nucleotides) that are more stable to make their RNAs, and placed their RNA within a lipid nanoparticle (LNP) delivery system in which LNPs fuse with the cell membrane to deliver the RNA to the cytoplasm.
Naked mRNA of kind used in the Pfizer/BioNTech and Moderna vaccines rely on a very simple mechanism in which the LNPs deliver the mRNA for the SARS-CoV-2 spike protein to muscle cells, which then use the mRNA as a template to make spike, which is then displayed on the surface of the cell to be recognized by the immune system. Some of the vaccine does manage to get to the regional lymph nodes, where they incite an immune reaction as well. This is part of the reason why COVID-19 vaccines have been found to produce false positives in mammography done too soon after vaccination by causing temporary enlargement of the lymph nodes under the arm, which is why mammography recommendations have changed to incorporate waiting at least six weeks after receiving an intramuscular COVID-19 vaccine in the deltoid muscle before undergoing screening mammography.
Before I go on, let me emphasize that, even though SARS-CoV-2 is an RNA virus, it is not the same thing as a retrovirus and the mRNA in LNPs is not the same thing as RNA in retroviruses. Whereas SARS-CoV-2, like most RNA-based viruses, uses an enzyme called an RNA-dependent RNA polymerase (RdRp) to make copies of its RNA genome from an RNA template, retroviruses use an enzyme called reverse transcriptase to produce a DNA copy of their genetic information, which can then integrate into the human genome. That’s why, in order to produce a suitably fear-mongering narrative, antivaxxers usually have to look very hard for highly unusual, artificial, or special case experiments. Guess what? Rose found them.
The dreaded “Cow-Pock” all over again
So let’s see what Jessica Rose wrote about these studies. Her message is, unsurprisingly, very much like that of antivaxxers 220 years ago:
I started to write this article yesterday but not one, but two papers of great interest to me have been published recently and require dissection and dissemination. They are entitled: “MSH3 Homology and Potential Recombination Link to SARS-CoV-2 Furin Cleavage Site” and “Intracellular Reverse Transcription of Pfizer BioNTech COVID-19 mRNA Vaccine BNT162b2 In Vitro in Human Liver Cell Line“, respectively.
Let me be clear here: These COVID-19 injectable products are perfect bioweapons – either by design or accident. Who cares which. The outcome is the same.
Regarding the first paper, Rose writes:
Background for future: MSH3 (MutS Homolog 3) is gene that encodes a protein that is responsible for maintaining the stability of our genomes and suppressing tumor formation. This protein is DNA mismatch repair (MMR) protein which means that it recognizes and repairs bad base (nucleotide) insertions, deletions and mis-incorporations that come about inherently as part of DNA recombination and replication as well as DNA repair. You might have heard me talk about this in some of my presentations in reference to the recently-published paper describing 2 enzymes characterized to be inhibited by the spike protein.
…we found that the spike protein localizes in the nucleus and inhibits DNA damage repair by impeding key DNA repair protein BRCA1 and 53BP1 recruitment to the damage site.
This more recent paper shows the presence of a 19 nucleotide-long sequence (19mer) that in fact, contains the sequence that encodes the furin-cleavage site of the SARS-nCoV-2 spike protein. In other fact, this 19mer has 100% sequence identity (100% query cover and matched identity anti-parallel complementarity 5′-3′) with patented sequences from as early as 2015. (I am checking on the link to MSH3.)1
Aha! There’s the conspiracy theory! (More on that later.) First, though, I’ll just note that this is far from the first time that I’ve seen the claim that COVID-19 vaccines somehow interfere with DNA repair. Last time around, it was the claim that the vaccine somehow interferes with a process known as non-homologous end joining (NHEJ) and thereby make those receiving it much more susceptible to cancer. That claim was deceptive. Indeed, the study was very poor quality and had no biological relevance to human cancer risk, although it did contribute to the fascist antivax claim that vaccines somehow “pollute” the blood, making the unvaccinated “purebloods“. Unsurprisingly, it’s exactly the paper Rose cited.
As for the second study, Rose is no less…off base:
Perhaps even more disturbing from a biological point of view, is something that many of us have hypothesized to be possible, has now been proven to be the case. Another new paper (link above) confirms that the Pfizer mRNA incorporates into human DNA. IN AS LITTLE AS 6 HOURS.
We detected high levels of BNT162b2 in Huh7 cells and changes in gene expression of long interspersed nuclear element-1 (LINE-1), which is an endogenous reverse transcriptase.
Huh is right.
Huh cells are ‘immortal’ liver tumor cells and grow ad-infinitum if you give them love. They are good for using in assays that involve viral propagation. LINE-1 is a reverse transcriptase that we carry and comprises ~17% of our genome! LINE-1 retrotransposons are necessarily active during embryogenesis are aberrantly active in tumorigenesis.
This claim, as has often been the case, rests on a kind of experiment that’s been done a number of times before to try to “prove” that the RNA virus SARS-CoV-2 can somehow mimic a retrovirus and insert its genetic sequence into the human genome, just like HIV. That’s why I’ll discuss this study first.
Artificial, thy name is this study
Before I discuss this study, let’s just reiterate that, for all the caveats and exceptions to the central dogma of molecular biology, for the vast majority of cases in normal mammalian cellular biology, information does not “flow backwards” from RNA to DNA. One of those exceptions, HIV and other retroviruses, requires two different enzymes to accomplish this “backwards” flow of genetic information. The first is the aforementioned reverse transcriptase, which “reverse transcribes” RNA sequences into DNA, destroying the RNA template in the process. However, that is not enough, as reverse transcriptase does not integrate the DNA strands thus produced into the human genome. A second enzyme is needed, a retroviral integrase. Integrases insert the double-stranded DNA produced by reverse transcriptase into the host’s chromosomal DNA; you can view this as a “point of no return,” after which the viral DNA becomes part of the host DNA, a form in which it is called a provirus, and a property of retroviruses that allow them to persist for so long in their hosts.
Retroviruses are not the only source of reverse transcriptase, as noted by Jessica Rose. Mammalian cells have very low levels of reverse transcriptase activity, so low that they’re usually not detectable under normal circumstances. One source is telomerase, which adds sequences known as telomere repeat sequences to the ends of chromosomes using an RNA template, to forestall the obligate chromosome shortening that occurs with each round of cellular replication. (Excessive telomerase activity is associated with the unlimited replicative potential of cancer.) Then there is LINE-1, mentioned by Rose and the focus of the paper.
LINE stands for long interspersed nuclear elements (LINEs). They are what are known as retrotransposons, also known as class 1 transposable elements or transposons via RNA intermediaries. Basically, retrotranposons can copy and paste themselves into different locations in the genome by making RNA and converting that RNA back into DNA through reverse transcription. Because it’s simple, I’ll “borrow” an illustration of how they work from Wikipedia:
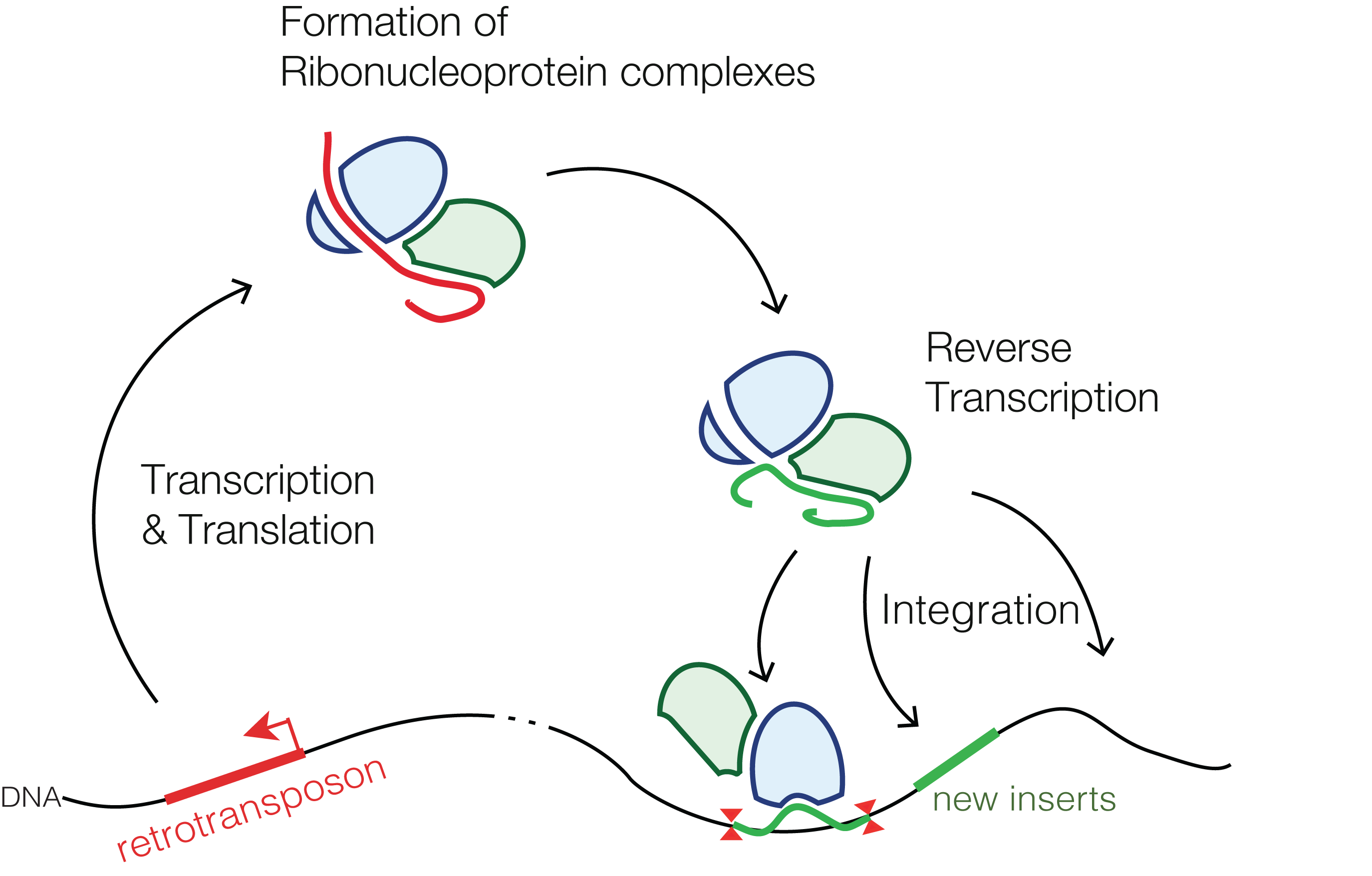
How retrotransposons copy and paste themselves into different locations in the genome.
You might reasonably be wondering at this point what LINE-1 could have to do with genetic sequences from the vaccine somehow getting into the human genome, thereby “permanently altering your DNA”. You’d be correct to wonder and likely would wonder even more if I told you that most LINEs in our genome are inactive and don’t make any functional enzyme and that they greatly prefer their own RNA and don’t randomly reverse transcribe just any old RNA. After all, retrotransposition (the process) requires that retrotransposons be able to replicate themselves and then paste the new copies elsewhere in the genome. It doesn’t matter that, as Rose points out, LINE-1 does make up approximately 17% of the human genome. Very little of it is active in normal physiology, although increased LINE-1 is associated with cancer, neuropsychiatric disorders, and retinal diseases. (I almost hated to say that because it gives antivaxxers ideas.)
So what does the second study cited by Rose claim? What did the investigators do? First, let’s look at the investigators’ rationale:
A recent study showed that SARS-CoV-2 RNAs can be reverse-transcribed and integrated into the genome of human cells [25]. This gives rise to the question of if this may also occur with BNT162b2, which encodes partial SARS-CoV-2 RNA. In pharmacokinetics data provided by Pfizer to European Medicines Agency (EMA), BNT162b2 biodistribution was studied in mice and rats by intra-muscular injection with radiolabeled LNP and luciferase modRNA. Radioactivity was detected in most tissues from the first time point (0.25 h), and results showed that the injection site and the liver were the major sites of distribution, with maximum concentrations observed at 8–48 h post-dose [26]. Furthermore, in animals that received the BNT162b2 injection, reversible hepatic effects were observed, including enlarged liver, vacuolation, increased gamma glutamyl transferase (γGT) levels, and increased levels of aspartate transaminase (AST) and alkaline phosphatase (ALP) [26]. Transient hepatic effects induced by LNP delivery systems have been reported previously [27,28,29,30], nevertheless, it has also been shown that the empty LNP without modRNA alone does not introduce any significant liver injury [27]. Therefore, in this study, we aim to examine the effect of BNT162b2 on a human liver cell line in vitro and investigate if BNT162b2 can be reverse transcribed into DNA through endogenous mechanisms.
This is thin gruel as a rationale. I note that I’ve discussed the cited study before, which involved the intravenous injection of a large amount of LNPs with a different mRNA than the vaccine’s spike protein mRNA, again an artificial design intended to make determination of the biodistribution of the LNPs possible given that in an intramuscular injection the vast majority of the mRNA remained at the injection site and in nearby lymph nodes.
I also note that it is not a new claim that SARS-CoV-2 itself is reverse transcribed in the infected cell to integrate with the host genome. This is a study from last summer that antivaxxers previously used to claim that, based on the supposed ability of SARS-CoV-2 to reverse transcribe, the vaccine could do the same. Let’s just say that this study was justifiably harshly criticized as not reproducible, very rare, and almost certainly artifacts of the experimental conditions used, given that appropriate controls weren’t used. To cite Ed Nirenberg again, no, SARS-CoV-2 is not reverse-transcribed to any significant extent, the publication of the study in PNAS notwithstanding.
I get the same vibes from this new study. So what did the authors do? They did indeed take Huh7 liver cells and expose them to the Pfizer/BioNTech vaccine (BNT162b2), at 200,000 cells/well in 24-well plates. Then they did this:
BNT162b2 suspension was then added in cell culture media to reach final concentrations of 0.5, 1.0, or 2.0 μg/mL. Huh7 cells were incubated with or without BNT162b2 for 6, 24, and 48 h. Cells were washed thoroughly with PBS and harvested by trypsinization and stored in −80 °C until further use.
After 48 hours, the cells were harvested. RNA was extracted for PCR, and in other experiments genomic DNA was extracted from the cells. Of particular importance however, is that the segment of the nucleic acid for the spike protein that was amplified by PCR was this:
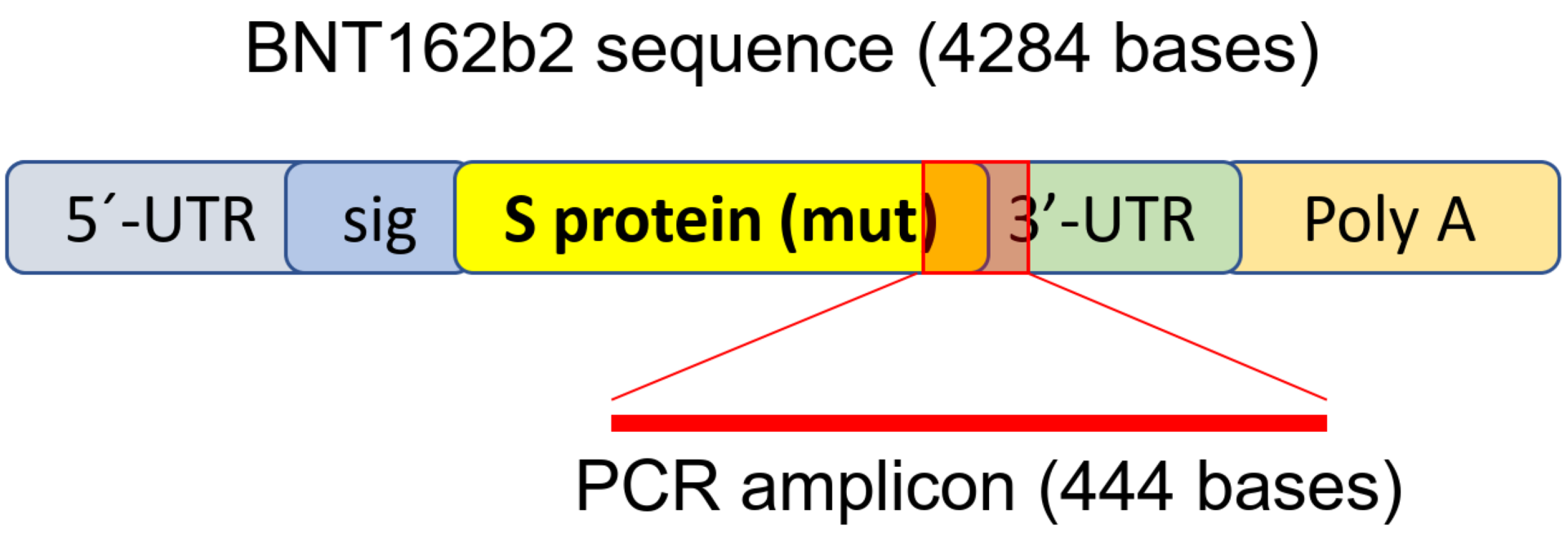
Spike amplicon, specifically the part of the sequence amplified by PCR in this experiment.
Why did they pick primers that amplified only this segment of the gene for spike protein? PCR efficiency drops off the longer the segment that is amplified, and a 444 base segment is actually rather long for quantitative real time PCR. In any event, this choice means that the only thing that can be said is that perhaps this segment of spike was reverse transcribed. Another thing to note is that a very high concentration of vaccine was used, microgram quantities for only 200,000 cells. That in and of itself is very artificial, but that’s not all that’s artificial. As Ed Nirenberg points out, Huh7 was derived from a liver cancer. Unsurprisingly, the Huh7 genome is, as is the case with many cancer-derived cell lines, really messed up.
He also notes that L-1 expression is substantially overexpressed in cancer (i.e., cancer cells have a lot more of it than normal cells).
In other words, the investigators stacked the deck by using a cell line that has a high level of LINE-1. If I were a peer reviewer for this study, I would have demanded that the investigators use a more genomically “normal” cell line. No cell line that is immortal—can propagate indefinitely—has a “normal” genome, but some have genomes that are less messed up than others. There are a number of respiratory cell lines, for instance, that could work, or what about simple primary cultures of vascular endothelial cells, such as HUVECs (human umbilical vein endothelial cells)? Why did they use only one cell line? In general, if you see a paper that uses only one cell line, be very, very skeptical, not just for COVID-19 but for any basic science studies.
So back to the paper. What did the authors find? Yes, they found that the vaccine, as expected, drove spike mRNA expression, leading to high levels in the cells, while not having much effect on LINE-1 expression, concluding that increased LINE-1 expression compared to control was observed at 6 h by 2.0 µg/mL BNT162b2, while lower BNT162b2 concentrations decreased LINE-1 expression at all time points. If you look at the figure, I call noise, because it doesn’t make a lot of physiologic sense that the lower vaccine concentrations would depress LINE-1 expression but lead to increased expression only at the 6 hour time point.
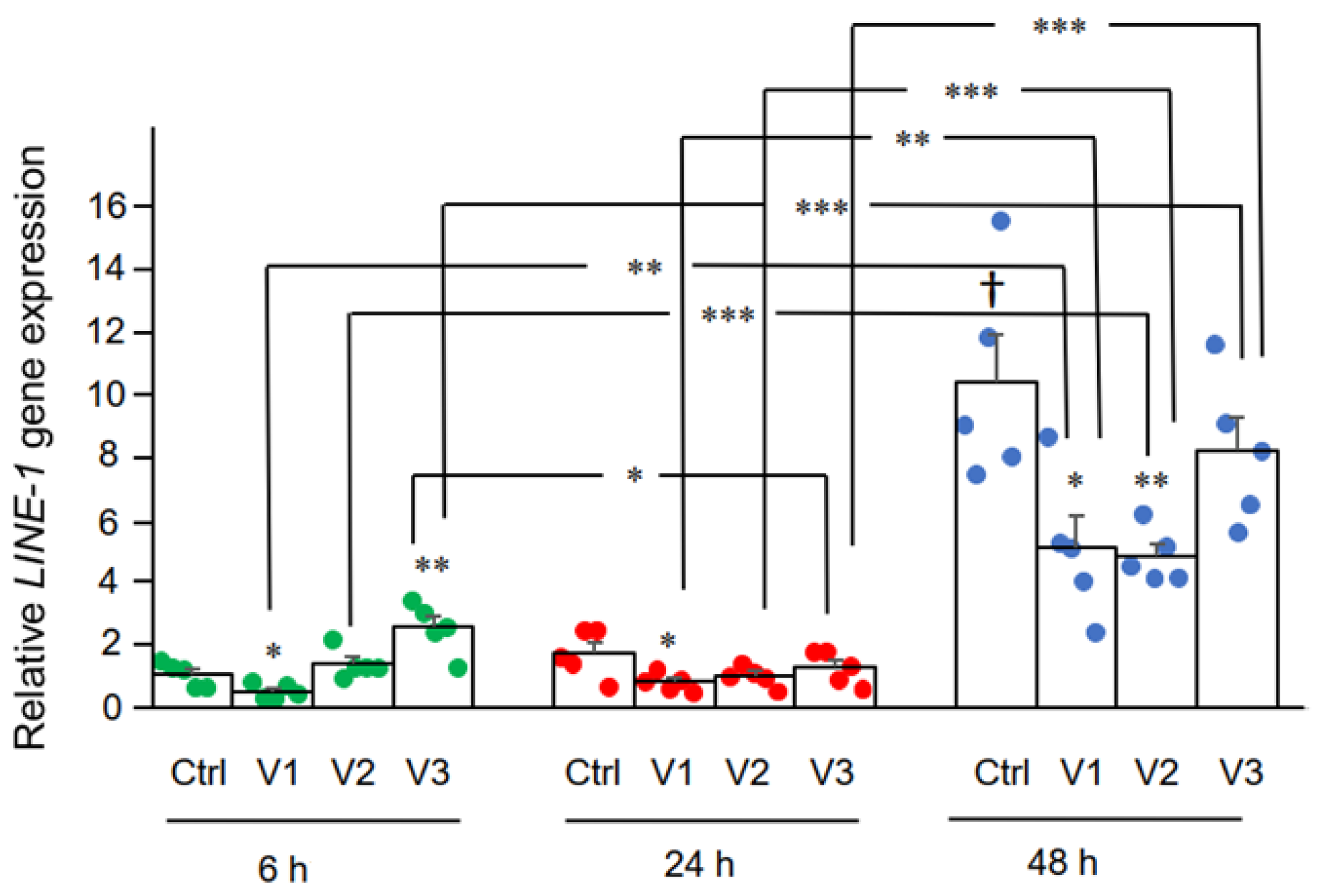
Whenever you see a graph like this, get out your BS detector.
Hilariously, this chart is the very same one included in Rose’s article, but she fails to see its shortcoming. Amusingly, the authors used two-tailed Student’s t-tests to compare these differences, which is not the correct statistical test for multiple time-dependent comparisons, and the finding of this result is most consistent with noise. Had I been a peer reviewer, I would definitely have called out the statistics used.
But what about reverse-transcribed DNA for spike? Yes, the authors did detect that in the genomic DNA isolated from the cells. They even sequenced the amplified segment and found that it was the same spike sequence targeted by the PCR primers. Checkmate, scientists! Not quite, and the authors even add some weasel words:
In this study we present evidence that COVID-19 mRNA vaccine BNT162b2 is able to enter the human liver cell line Huh7 in vitro. BNT162b2 mRNA is reverse transcribed intracellularly into DNA as fast as 6 h after BNT162b2 exposure. A possible mechanism for reverse transcription is through endogenous reverse transcriptase LINE-1, and the nucleus protein distribution of LINE-1 is elevated by BNT162b2.
Note that this study most definitely did not show that this reverse transcription had anything to do with LINE-1, leaving the authors to speculate. They could have presented evidence that LINE-1 was responsible, perhaps by knocking it out to produce cells that don’t make it or using siRNA that targets the LINE-1 mRNA to decrease its level, and showing that that it blocked the reverse transcription of spike. They didn’t do that. So they speculate, and antivaxxers ignore that this is speculation to present it as a fact that SARS-CoV-2 is reverse transcribed through the reverse transcriptase activity of LINE-1.
Next:
Our study shows that BNT162b2 can be reverse transcribed to DNA in liver cell line Huh7, and this may give rise to the concern if BNT162b2-derived DNA may be integrated into the host genome and affect the integrity of genomic DNA, which may potentially mediate genotoxic side effects. At this stage, we do not know if DNA reverse transcribed from BNT162b2 is integrated into the cell genome. Further studies are needed to demonstrate the effect of BNT162b2 on genomic integrity, including whole genome sequencing of cells exposed to BNT162b2, as well as tissues from human subjects who received BNT162b2 vaccination.
This led to some epic handwaving:
The cell model that we used in this study is a carcinoma cell line, with active DNA replication which differs from non-dividing somatic cells. It has also been shown that Huh7 cells display significant different gene and protein expression including upregulated proteins involved in RNA metabolism [56]. However, cell proliferation is also active in several human tissues such as the bone marrow or basal layers of epithelia as well as during embryogenesis, and it is therefore necessary to examine the effect of BNT162b2 on genomic integrity under such conditions. Furthermore, effective retrotransposition of LINE-1 has also been reported in non-dividing and terminally differentiated cells, such as human neurons [57,58].
Sure thing, guys, but no. This is, as I said, just handwaving.
As Ed Nirenberg asks, why didn’t they bother to do the necessary follow-up experiments to determine if this DNA sequence is actually integrated into the genome? Come to think of it, why didn’t they do PCR of the entire spike sequence to show that the full length sequence had been reverse-transcribed? Or even just do PCR of different fragments from the spike sequence? It boggles the mind.
None of this stops Rose from going straight off the end of the plank of science to this conclusion:
LINE-1 retrotransposons are also involved during early embryonic development. Since LINE-1 expression levels are significantly increased then what effect is this over-expression having on embryogenesis?
We found that too much or too little LINE-1 expression caused development to come to a halt. This means that the precise timing and level of retrotransposon expression is critical for the development of the embryo.”
I need a walk. This article will be updated.
I can hardly wait for Rose’s “updates”, given how far she had to reach to find some rationale to take a highly artificial experiment that almost certainly doesn’t show that the mRNA for the SARS-CoV-2 spike used in COVID-19 vaccines is reverse transcribed under normal conditions, much less “integrated” into the genome of the cells in which it finds itself. I’m guessing that her “updates” will be as hilariously off base as her original post.
But what about the first study?
Moderna and the “lab leak”
The second paper cited by Rose turns out to be all about the “lab leak” conspiracy theories. It’s not about the more plausible variant of the “lab leak” concept (but still highly unlikely compared to a natural origin) in which a naturally occurring bat coronavirus somehow escaped the virology lab at Wuhan, thereby starting the pandemic, but rather the utter bonkers idea that SARS-CoV-2 is an “engineered” coronavirus that escaped the laboratory, thanks to “gain of function” research. Of course this version is a different twist on the same idea, specifically that the finding of a short DNA sequence from a larger sequence patented by Moderna years ago as part of its cancer research effort in the sequence in the spike protein mRNA used in the Moderna vaccine is slam-dunk evidence for the “lab leak” hypothesis. Let’s just say that it’s not.
The article is a perspective article, which means it’s basically the peer-reviewed scientific equivalent of an op-ed article. I also can’t help but wonder how the authors got something like this published on the basis of doing some BLAST searches of the Genbank database, something basically anyone with an Internet connection can do to see if nucleotide and protein sequences exist in all the ones reported to the database. I used to do BLAST searches all the time, and have even done a few going way, way back to the beginning of the pandemic, when James Lyons-Weiler tried to “prove” that there were sequences from a common plasmid in SARS-CoV-2, thus demonstrating that it was “engineered.” (Hint: He failed.)
The op-ed asserts:
A peculiar feature of the nucleotide sequence encoding the PRRA furin cleavage site in the SARS-CoV-2 S protein is its two consecutive CGG codons. This arginine codon is rare in coronaviruses: relative synonymous codon usage (RSCU) of CGG in pangolin CoV is 0, in bat CoV 0.08, in SARS-CoV 0.19, in MERS-CoV 0.25, and in SARS-CoV-2 0.299 (9).
A BLAST search for the 12-nucleotide insertion led us to a 100% reverse match in a proprietary sequence (SEQ ID11652, nt 2751-2733) found in the US patent 9,587,003 filed on Feb. 4, 2016 (10) (Figure 1). Examination of SEQ ID11652 revealed that the match extends beyond the 12-nucleotide insertion to a 19-nucleotide sequence: 5′-CTACGTGCCCGCCGAGGAG-3′ (nt 2733-2751 of SEQ ID11652), such that the resulting mRNA would have 3′- GAUGCACGGGCGGCUCCUC-5′, or equivalently 5′- CU CCU CGG CGG GCA CGU AG-3′ (nucleotides 23547-23565 in the SARS-CoV-2 genome, in which the four bold codons yield PRRA, amino acids 681–684 of its spike protein). This is very rare in the NCBI BLAST database.
The correlation between this SARS-CoV-2 sequence and the reverse complement of a proprietary mRNA sequence is of uncertain origin. Conventional biostatistical analysis indicates that the probability of this sequence randomly being present in a 30,000-nucleotide viral genome is 3.21 ×10−11 (Figure 2).
Wow. That sounds damning, doesn’t it?
Of course, those following various “lab leak” hypotheses for the origin of SARs-CoV-2 will immediately recognize the reference to the furin cleavage site. An interesting feature of the SARS-CoV-2 spike protein is that it consists of two subunits and, between those two subunits, S1 and S2, sits a site where a human protein called furin cleaves the protein, resulting in the two functional subunits. In fact, you might even recognize the claim that the two successive CGG codons, coding for two arginine residues in the furin cleavage site, is a rare codon usage. Let’s just say that, in terms of the pandemic, this is a hoary old bit of SARS-CoV-2 conspiracy mongering dating back to very early in the pandemic and popularized by science writer-turned-COVID-19-conspiracy theorist Nicholas Wade. Moreover, the term “randomly present in a 30 kb viral genome” is doing a lot of heavy lifting, mainly because no one is saying that it’s random. Do the authors think that beta coronaviruses (of which SARS-CoV-2 is one) are made up of random sequences unrelated to each other? Of course not! They’re highly related.
Indeed, it has been pointed out just how off-base the probability argument is:
Lawrence Young, Ph.D., a virologist at the University of Warwick, said it was interesting but probably not significant enough to suggest the virus was manipulated in a laboratory. “We’re talking about a very, very, very small piece made up of 19 nucleotides. So it doesn’t mean very much to be frank, if you do these types of searches you can always find matches. Sometimes these things happen fortuitously, sometimes it’s the result of convergent evolution (when organisms evolve independently to have similar traits to adapt to their environment). It’s a quirky observation but I wouldn’t call it a smoking gun because it’s too small. It doesn’t get us any further with the debate about whether COVID was engineered.”
Simon Clarke, Ph.D., a microbiologist at Reading University, also questioned the one-in-three trillion statistics, saying, “There can only be a certain number of [genetic combinations within] furin cleavage sites. They function like a lock and key in the cell, and the two only fit together in a limited number of combinations. So it’s an interesting coincidence but this is surely entirely coincidental.”
If you’re a conspiracy theorist, of course, there is no such thing as a coincidence, at least if it’s about something you want to believe to be true. In any event, this is exactly correct. The wrong argument to make is how common such a 19 nucleotide sequence would occur randomly in a viral genome. You have to take into account function, which greatly constrains the sequences one can find, plus how short this sequence is, which makes it very much more likely that it did indeed occur by chance.
As I’ve discussed before, it turns out that a CGGCGG sequence is not all that uncommon. It has been found in other coronaviruses, for example, some isolates of MERS coronavirus. Furin cleavage sites are also found in a number of other coronaviruses, as discussed in this recent review article. Although uncommon, furin cleavage sites are not so uncommon in coronaviruses as to be any sort of strong evidence of laboratory manipulation. Moreover, there are known natural mechanisms by which such a sequence could have arisen, as has been discussed extensively on Twitter and elsewhere. But what about that 19-nucleotide sequence?
I will note, however, that the claim made in this op-ed is a rather interesting spin on the same old claims about the SARS-CoV-2 furin cleavage site in that I haven’t seen it before. In this case, the authors are claiming that this 19 nucleotide sequence found in MSH3, a DNA repair gene, is the very same sequence patented by Moderna seven years ago and found in the furin cleavage site of the spike sequence used in the Moderna vaccine, with the implication that SARS-CoV-2 was “engineered”:
The proprietary sequence SEQ ID11652, read in the forward direction, encodes a 100% amino acid match to the human mut S homolog 3 (MSH3) (9). MSH3 is a DNA mismatch repair protein (part of the MutS beta complex) (11). SEQ ID11652 is transcribed to a MSH3 mRNA that appears to be codon optimized for humans (12). We did not find the 19-nucleotide sequence CTCCTCGGCGGGCACGTAG in any eukaryotic or viral genomes except SARS-CoV-2 with 100% coverage and identity in the BLAST database (Supplementary Tables 1–3).
A claim that the authors make explicit:
The absence of CTCCTCGGCGGGCACGTAG from any eukaryotic or viral genome in the BLAST database makes recombination in an intermediate host an unlikely explanation for its presence in SARS-CoV-2.
Ergo, this sequence must have been “engineered”. Add to that the Moderna patent and checkmate, right? Not so much. For one thing, this sequence is the reverse complement of the sequence found on the furin cleavage site. What does that mean? It’s on the opposite strand, the strand that doesn’t code for protein. The authors do a lot of handwaving to try to explain this, mainly by claiming that “cells co-transfected with a SARS-like virus expressing RdRp could attach to this 19-nucleotide sequence (15) and permit integration of a fragment from the negative strand into the viral genome, including the FCS, despite being on the opposite strand of the open reading frame,” RdRp being the RNAse-dependent RNA polymerase mentioned early in this post. Perhaps, but this comes across to me more as an attempt to wave away the very substantive criticism that a sequence that isn’t the strand that codes for the actual protein.
Just for yucks, I did some BLAST searches myself, and after doing a number of them I concluded that this result was not easy to come by. I had to search the sequence patented by Moderna versus SARS-CoV-2 with the “loosest” parameters that allowed for the least degree of similarity; otherwise there were zero matches, largely because stricter parameters only find longer stretches of sequence similarity. That’s why I now rather suspect that the investigators searched the sequence for SARS-CoV-2 versus every sequence ever patented by Moderna, and the best they could come up with was this short 19 amino acid match, after which, even though it was the reverse complement and not even on the strand that codes for the protein, started searching other Moderna patents for the same 19mer and found a few more hits.
Making me even surer that this is random is Rose’s own further observations:
Most disturbing, however, is that HZ246785.1 was patented 7 years ago by MODERNA THERAPEUTICS (2015) and more recently by ModernaTX Inc (2017/2018). Other patents for this same 19mer were filed by CAMBIA (2015) and CureVac AG (2021). A shorter version with 89% query and 100% matched identity were found in patents filed by Monsanto Technology LLC (2016) and Metanomics GmbH (2015). Just noting some familiar names here. Not making any claims.
Then, thankfully, bioinformatician Moreno Colaiacovo provided a lengthy explanation dating back to December why there’s nothing to see here; so I’ll cite his brief discussion in its entirety:
When challenged, Colaiacovo noted:
And:
Think of it this way. Whoever initially found this 19 nucleotide sequence did a lot of work to find it. Yet, this is the best they could come up with as slam dunk “evidence” that SARS-CoV-2 was engineered by Moderna, to the point where they have to do serious contortions make such a short stretch seem nefarious? Another way to think of it is just how unlikely it is that this shared 19-mer is proof of some sort of engineering or that Moderna “knew” about SARS in 2016. Again think of how unlikely the implied necessary scenario would be: Somehow during an experiment cells transfected with the sequence in the patent were infected by a SARS-like virus, and then there was a recombination event that led to SARS-CoV-2 with a furin cleavage site containing that sequence—and not even on its coding strand, but on its reverse complement strand! This is reaching homeopathy-levels of implausibility.
Everything old is new again
As I like to say, in antivaxland, everything old is new again in the age of COVID-19. However, as the pandemic grinds on, entering its third year, even everything old that was new again when COVID-19 struck is becoming old. The idea that COVID-19 vaccines “permanently alter your DNA” has now spawned a number of—if you’ll excuse my use of the term—variants. So has the version of the “lab leak” hypothesis that asserts that SARS-CoV-2 was somehow “engineered”, this variant adding a conspiracy theory that implies that one of the manufacturers of the first successful COVID-19 vaccines must have somehow “known” the sequence of SARS-CoV-2 nearly four years before the pandemic. What Jessica Rose is promoting, aided and abetted by these awful studies published in bottom feeding journals, is simply helping to spread variants of these two conspiracy theories.