{kind=link}
 A new study looked at clinical trials for neuropathic pain over the last 23 years and found that the response of subjects in the placebo group has been increasing over time, but only in the United States. The cause of this increase is unknown, and has provoked a fascinating discussion about the nature of placebos and their role in medical research.
A new study looked at clinical trials for neuropathic pain over the last 23 years and found that the response of subjects in the placebo group has been increasing over time, but only in the United States. The cause of this increase is unknown, and has provoked a fascinating discussion about the nature of placebos and their role in medical research.
What is the placebo effect?
We have discussed the placebo response at length here at SBM because the concept is critical to understanding clinical science, and it is largely misunderstood. Most often it is presented as a mind-over-matter response to the expectation of benefit. Proponents of worthless treatments often hype the placebo response as if it can have real healing power, when the evidence shows it does not.
In reality, there are a large number of placebo effects and the phenomenon is quite complex. In clinical trials “the placebo effect” is whatever happens in the placebo group of the study, the group receiving an inactive treatment. This is not one effect, however, but a complex combination of many effects.
These placebo effects include the non-specific effects of participating in a clinical trial, regression to the mean, reporting bias, improved mood from the hope of being treated and getting attention from a practitioner, researcher bias, and other effects. Placebo responses vary by the outcome being measured. In general pain and other subjective outcomes have a larger placebo response than objective hard outcomes.
The evidence suggests that placebo effects are mostly an illusion of doing clinical trials. They are artifacts, not real healing effects. Any real placebo benefits are due to such things as taking better care of yourself and being more compliant with your treatments in general because you are being watched in a clinical trial.
Placebos “getting stronger”
What the current research shows is that the size of the response in the placebo arm of US clinical trials looking at drugs to treat neuropathic pain has increased steadily over the last 23 years (1990 to 2013). This has reduced the margin of benefit for the active drugs, essentially making it more difficult to demonstrate a statistical benefit.
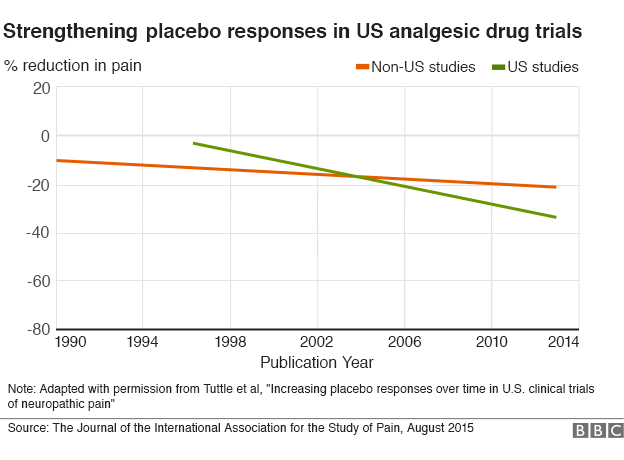
The data is fairly clear. The only real question is what is causing this trend. Here even the authors of the article disagree. The hypotheses seem to fall into two main categories – Americans are having a greater psychological response to placebos, or the way that clinical trials are being conducted is resulting in a greater placebo artifact. I tend to find the latter explanations more compelling.
One cultural factor that has been suggested is that drug advertising has subtly made Americans have higher expectations in the effectiveness of drugs overall. This seems like a bit of a stretch.
I could not find any specific study addressing this question, but there are a number of studies looking at public attitudes toward direct-to-consumer drug advertising. One survey found that advertising does affect consumer preference for a branded drug, but that consumers do not feel the advertised drug is superior to another option offered by their physician. This would seem to undercut the above hypothesis, but again this should be considered an open question.
Other speculations focus on the trials themselves. The authors did find that clinical trials in pain have been getting bigger and longer over the study period, and that the size of the study is associated with a larger placebo response. This could just be due to the fact that both trends were occurring over the study period, without the one causing the other.
If the change in the size of the placebo response is due to the way clinical trials are designed, is this a good thing or a bad thing? In other words, are trials showing less of a difference between treatment and placebo because they are getting better (implying that older studies were more false positive) or because they are getting worse (newer studies are more false negative)? This is a critical question.
One possibility that has been raised is that often pharmaceutical companies turn over the running of their clinical trials to private companies. These companies are motivated to recruit large numbers of subjects. This may motivate them to fudge the inclusion criteria by encouraging prospective subjects to exaggerate their symptoms. The exaggeration would then go away once they are in the trial, resulting in an apparent treatment effect. This would affect both the treatment and placebo arms of the study, but would statistically obscure the treatment effect (which would be proportionally smaller).
The way subjects are being treated in trials is also changing over time. They are getting more attention, perhaps more encouragement, and their overall experience in the trial is better. All of these things would magnify their placebo response to the experience.
How to fix it?
It is difficult to know how to fix the problem of growing placebo responses obscuring treatment effects without knowing the cause(s) (and even if it’s a problem). Reducing possible artifacts, however, is generally a good idea and might fix the problem (and provide evidence for the cause(s)).
For example, subjects in a clinical trial could be given more balanced information about what to expect. They could be given, for example, statistically accurate information about the chance of getting the drug vs placebo, the probability that the drug works and the percentage of subjects for whom drugs typically work. This would shift subject expectations. It may also hamper recruitment, but recruitment number does not seem to be an issue.
Steps could be taken also to make it more difficult for recruiters to fudge inclusion criteria. Perhaps they are not told what the criteria are, only what information to gather. Then a centralized unit will review the data and determine if the criteria are met. Careful attention can also be paid to inclusion criteria, to make them as objective as possible.
Another approach already being used is to have a placebo lead-in period. In this study design all subjects are given a placebo prior to randomization, and those that have a placebo response are then statistically excluded from the primary outcome. Those who did not have a significant placebo response are randomized to treatment vs placebo. The effectiveness of this approach has yet to be determined, with results so far being mixed.
Conclusion: Tuttle et al. raises more questions than it answers
The new study provokes more questions than it answers, which is the sign of a good study. It is yet more evidence that placebo effects are complicated and are largely due to artifacts in the way clinical trials are designed and executed.
The technology of clinical trials is getting more sophisticated, and this is yet one more factor that needs to be taken into consideration. It is potentially a huge problem, as hundreds of millions of dollars of development costs can be wasted if clinical trials are coming up false negative because of a subtle flaw in their execution.
Another lesson to derive from this controversy is how difficult it is to determine if a treatment works. This is precisely why anecdotal evidence is mostly worthless, and cannot be used as definitive evidence of efficacy. Even under careful scientific conditions it is difficult to tease out all the various placebo effects. It is virtually impossible in anecdotal conditions.