
{kind=link}
I knew it. I just knew it. I knew I couldn’t get through October, a.k.a. Breast Cancer Awareness Month, without a controversial mammography study to sink my teeth into. And I didn’t. I suppose I should just be used to this now. I’m referring to the latest opus from H. Gilbert Welch and colleagues that appeared in the New England Journal of Medicine last week, “Breast-Cancer Tumor Size, Overdiagnosis, and Mammography Screening Effectiveness.” Yes, it’s about overdiagnosis, something I’ve blogged about more times than I can remember now, but it’s actually a rather interesting take on the issue.
Before 2008 or so, I never gave that much thought to the utility of mammographic screening as a means of early detection of breast cancer and—more or less—accepted the paradigm that early detection was always a good thing. Don’t get me wrong. I knew that the story was more complicated than that, but not so much more complicated that I had any significant doubts about the overall paradigm. Then, in 2009, the United States Preventative Services Task Force (USPSTF) dropped a bombshell with its recommendation that mammographic screening beginning at age 50 rather than age 40 for women at average risk of breast cancer. Ever since then, there have been a number of studies that have led to a major rethinking of screening, in particular screening mammography and PSA testing for prostate cancer. It’s a rethinking that affects discussions even up to today, with advocates of screening arguing that critics of screening are killing patients and skeptics of screening terming it useless. Depending on the disease being screened for, the answer usually lies somewhere in between. Basically, screening is not the panacea that we had once hoped for, and the main reason is the phenomenon of overdiagnosis. Before I go on, though, remember that we are talking about screening asymptomatic populations. If a woman has symptoms or a palpable lump, none of this discussion applies. That woman should undergo mammography.
Overdiagnosis, a(nother) primer
Basically, overdiagnosis is a phenomenon that can confound any screening program in which large populations of asymptomatic patients are subjected to a diagnostic test to screen for a disease. The basic concept is that there can be preclinical disease that either does not progress or progresses so slowly that it would never threaten the life of the patient within that patient’s lifetime, yet the test picks it up. Because we don’t have tests that can predict which lesions picked up by such a screening test will or will not progress to endanger the patient, physicians are left with little choice but to treat each screen-detected lesion as though it will progress, resulting in overtreatment and the resulting iatrogenic harms. This situation is very much the case for mammography and breast cancer, for example, for which there is evidence that as many as one in five to one in three screen-detected (as opposed to cancers detected by symptoms or a mass) breast cancers are overdiagnosed. As a result, physicians are much less confident in traditional recommendations for screening mammography than we once were. And you can add to that the phenomenon of lead time bias, in which earlier detection doesn’t actually impact survival but only gives the appearance of prolonged survival.
The rate of overdiagnosis due to mammography is probably higher than previously thought
With that background in mind, let’s take a look at Welch’s latest. The basic idea behind the study is rooted in the key assumption behind mammography, which is that the detection of small tumors that have not yet become palpable, will prevent progression and, over time, lead to fewer large or more advanced tumors being diagnosed. Welch et al also note the difference between efficacy (how well a treatment or screening test works in randomized clinical trials) and effectiveness (how well an intervention works when “unleashed” in the community):
Although it may be possible to show the efficacy of screening mammography in reducing cancer-specific mortality in the relatively controlled setting of randomized trials, those trials may not accurately reflect the actual effectiveness of screening when it is used in clinical practice. Differences between efficacy and effectiveness with respect to the benefit of screening may be particularly stark when the treatments administered in practice have markedly changed from those administered in the trials that led to the implementation of widespread screening. Furthermore, although trial data may provide an assessment of some negative consequences of screening, such as false positive results and associated diagnostic procedures, such assessments may understate what actually occurs when screening is implemented in the general community. The collection of data regarding other harms, such as overdiagnosis (i.e., tumors detected on screening that never would have led to clinical symptoms), requires additional long-term follow-up of trial participants, and those data are often either not available or they reflect patient follow-up and testing practices from decades earlier.
This actually reflects a key controversy in breast cancer treatment. We know that breast cancer mortality has been steadily declining since 1990 or so, roughly 30% since then. The controversy is not over whether breast cancer mortality is declining. It is. The controversy is over what’s the cause: screening, better treatment, or some combination of the two. Indeed, Welch et al even note that in models used by the Cancer Intervention and Surveillance Modeling Network the estimates of the contribution of screening to the observed reduction in breast-cancer mortality range from as little as 28% to as much as 65%. To approach this question, Welch et al decided to take a very simple approach. At least, the question is simple. They decided to look at a metric that’s been measured for many years: The size of breast cancer tumors at the time of diagnosis. The hypothesis, of course, is that mammography should produce a shift towards smaller tumors. So Welch looked at breast cancer diagnoses in the SEER Database from 1975 to 2012, which encompasses the time period before the advent of mass mammographic screening in the US, the period during which screening programs were implemented, and the period after. Size at diagnosis was recorded and divided into the following groups:
- Less than 1 cm
- 1 – 1.9 cm
- 2 – 2.9 cm
- 3 – 3.9 cm
- 5+ cm
There were a fair number of complexities, the main one having to correct for missing tumor sizes in the database, which were common decades ago but became less common as time went on. Without going into the details, I can point out that the results were as follows:
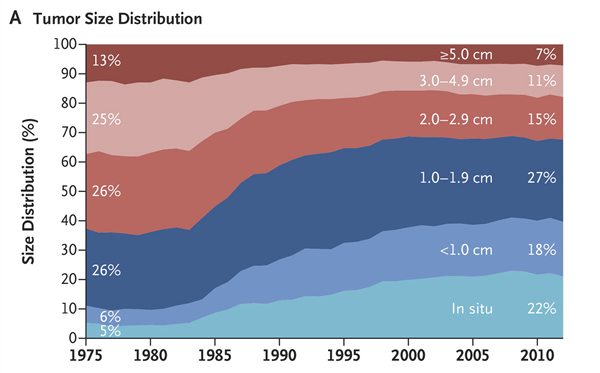
At first glance, this looks as though mammography is doing exactly what it’s supposed to be doing. Notice how, beginning in the early 1980s, there was a shift in the distribution of tumor size at diagnosis from larger tumors to smaller tumors. For example, the combination of in situ and tumors less than 1 cm increased from 11% to 40%, while the percentage over 3 cm in size decreased from 38% to 18%. So far, so good, right?
Not exactly:
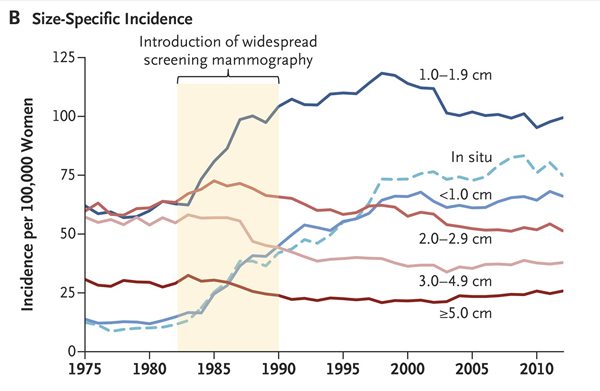
The observation here is that the increase in the number of small tumors was considerably greater than the decrease in the number of large tumors. Indeed, the results look very much like the results of Welch’s last study, which compared the incidence of advanced versus early cancers and found basically the same thing: The introduction of mammographic screening was associated with a greater increase in the incidence of early cancers than there was a decrease in the incidence of more advanced cancers. Thus, we have fairly consistent results showing in two different studies that, while the introduction of mammographic screening appears to have resulted in a decrease in the incidence of larger/more advanced tumors, it resulted in a far larger increase in the diagnosis of smaller/less advanced tumors. In the last study, Welch estimated the rate of overdiagnosis to be around 30%. What about in this study?
This was the magnitude of the shift:
However, this shift in size distribution was less the result of a substantial decrease in the incidence of large tumors and more the result of substantial increases in the detection of small tumors(Figure 2B). Nevertheless, modest decreases were seen in the incidence of large tumors. The changes in size-specific incidence of breast cancer after the introduction of screening mammography are shown in Table 1. The incidence of large tumors decreased by 30 cases of cancer per 100,000 women (from 145 to 115 cases of cancer per 100,000 women), and the incidence of small tumors increased by 162 cases of cancer per 100,000 women (from 82 to 244 cases of cancer per 100,000 women). Assuming that the underlying burden of clinically meaningful breast cancer was unchanged, these data suggest that 30 cases of cancer per 100,000 women were destined to become large but were detected earlier, and the remaining 132 cases of cancer per 100,000 women were overdiagnosed (i.e., 30 subtracted from 162).
This is an estimate of overdiagnosis even greater what previous studies have found, roughly 80% or 132/162 additionally detected tumors were overdiagnosed, and the estimated decrease in mortality attributable to mammography was 12 per 100,000 women in the earlier time period after mammographic screening was introduced. In more recent years, with better treatment, the estimated reduction in mortality was smaller, around 8 per 100,000. In comparison, the estimated reduction in mortality due to better treatment was 17 per 100,000. Thus, overall, better treatment has reduced mortality from breast cancer more than screening has. However, that’s not to say that mammography doesn’t save lives. It does. It’s just that the effect is more modest than previously believed.
Here’s a video in which Welch explains his results:
The case against the case against mammography
Not surprisingly, not everyone accepted Welch’s results. For instance, Elaine Schattner, a physician and journalist who was diagnosed with breast cancer by her first mammography at age 42, was not impressed, taking to her Forbes blog to provide what she calls “The Case Against the Case Against Mammography.” Unfortunately, her objections to the study do not stand up to scrutiny. For instance, she begins:
The world’s leading medical journal has published yet another skewed analysis of mammography, overdiagnosis and breast cancer trends. I’m disappointed that the New England Journal of Medicine would promote such an assumption-riddled, estimate-loaded piece to dissuade readers of screening’s value.
Note the loaded language. Dr. Schattner characterizes Welch’s analysis as “skewed” and refers to it as “assumption-riddled” and “estimate-loaded,” but nowhere in her op-ed does she actually identify which specific assumptions behind the study or estimates used she questions and why or why those assumptions or estimates invalidate Dr. Welch’s findings. Don’t get me wrong. Welch’s study is not perfect, but if you’re going to portray it as a hit piece against mammography (which it is not, by the way), you really do need to do a lot better than that.
Next, Dr. Schattner simply “restates” her “three go-to points on why this mammography ‘news’ should not influence any woman’s decision”:
1. The overdiagnosis campaign reflects a lack of respect for women’s capacity to make rational choices about their health. If a woman learns she has a breast tumor, she can weigh the information and consult with her doctor about the best plan forward.
I couldn’t disagree with this assertion more. First, I resent the dismissive characterization of studies like this as the “overdiagnosis campaign.” It’s a term that intentionally portrays scientists like Dr. Welch as being hopelessly biased and perhaps even having less-than-reputable motivation, a recurring theme among defenders of mammography. I’ve published (once) with Dr. Welch; I know this not to be true. Also, personally, I always thought that the negative reaction against any study that raised questions about how effective mammography is in preventing death from breast cancer tended to betray a lack of respect for women’s capacity to make rational choices about their health. After all, why wait until a woman is diagnosed with a mammography-detected cancer before allowing her to “weigh the information and consult with her doctor about the best plan forward”? Why wait until a screen-detected cancer that could well have been overdiagnosed is found? Doesn’t respecting a woman’s ability to weigh the evidence and choose for herself involve also respecting her ability to weigh studies like this? A woman and her doctor, using the information that studies like Welch’s provide can do that before the woman decides if she wants to begin a screening campaign. Moreover, Welch himself is not opposed to screening mammography or seeking to tell women not to undergo the test. He’s trying to provide them the very information they need to decide whether the test is right for them.
Next up:
2. The report rates old technology. The most recent mammograms in this “ecological” study would be from 2002. Mammography equipment has since shifted to digital, among other leaps forward.
While this is true, its relevance is questionable. After all, better, more sensitive mammography equipment of the type we have now, if anything, could just as easily exacerbate, not alleviate, the problem of overdiagnosis. In fact, more sensitive detection usually exacerbates overdiagnosis.
Then:
3. The paper ignores differences among radiologists, and the potential to improve screening outcomes in the U.S. population by assuring that all breast imaging is done by doctors who do only that.
Again, this is an observation of little relevance to Dr. Welch’s analysis. Remember, overdiagnosis is a cancer. In overdiagnosis, a mammogram detects a lesion, that lesion is biopsied, and it comes back histologically as ductal carcinoma in situ or invasive cancer. A breast cancer can’t be overdiagnosed if there isn’t a lesion on mammography that is biopsied. Dr. Schattner seems to assume that better, more specialized radiologists doing only mammography will not flag lesions that will turn out to be overdiagnosed, but that’s an incorrect assumption for one very simple reason. There is no difference, mammographically, between breast cancers that are overdiagnosed and those that will progress to endanger the life of the woman. No matter how well trained the radiologist is, he or she can’t tell the difference. All the radiologist can tell is that there’s a suspicious mass, bit of architectural distortion, or cluster of microcalcifications requiring biopsy. All the pathologist can tell is whether, on histology, there is DCIS or cancer there, or not.
The same is true of her other criticisms. For instance, Dr. Schattner also criticizes Welch for not considering “alternative and new screening methods: breast ultrasound to evaluate dense breasts, 3D mammography, MRI or molecular breast imaging.” That’s like criticizing a golf course for not being a baseball diamond. That is not what the study was about. It was about mammography. But to address her objection, none of these tests has yet been validated as tools for the mass screening of asymptomatic populations, and they all have their own problems. MRI is very expensive relative to mammography and too sensitive, not to mention that it also requires intravenous contrast. Widespread adoption of MRI would cost a lot more money than anyone’s willing to spend, and it would likely exacerbate, not alleviate, the problem of overdiagnosis. Molecular breast imaging (MBI) uses a radiolabeled tracer and operates much like PET or bone scanning. Given that, it doesn’t show anatomy very well and it too could be too sensitive. It’s been oversold. 3D mammography is also more expensive. It might be useful, but, again, it hasn’t been validated as a screening tool and it is unclear whether it would alleviate the problem of overdiagnosis given that the 3D images are constructed from mammographic images and thus suffer from the same problems as mammography and that 3D mammography is touted as “finding more tumors,” which, again, could exacerbate, not alleviate, overdiagnosis.
Dr. Schattner also mentions Welch’s study “skips over advances in pathology” and that doctors “have tools, now in everyday use, to evaluate biopsies, to distinguish aggressive tumors from slow-growing ones to avoid overtreatment.” I’d sure love to know what those advances and tools are, because I am a breast cancer surgeon and I don’t know of any test in everyday use that is reliable enough to tell me which mammography-detected breast cancer or DCIS lesion is safe to watch and which needs immediate treatment. All the pathologist looking at the biopsy of that mammographic abnormality can tell histologically is that it is breast cancer. What neither of them can tell is if it is overdiagnosed breast cancer (i.e., cancer that will never progress or will progress so slowly that it never becomes a problem in the patient’s lifetime) or breast cancer requiring treatment. As a breast cancer surgeon, when confronted with a biopsy-proven histological diagnosis of cancer in a patient, I have no choice but to treat that cancer as though it threatens the life of the patient because I have no reliable test to tell me which ones are safe or not. I am aware that some cutting-edge surgeons (if you’ll excuse the term), like Dr. Laura Esserman do sometimes use watchful waiting for low grade DCIS, but most surgeons don’t (yet) have the intestinal fortitude for that, and I doubt that even Dr. Esserman’s intestinal fortitude is up to the level where she would use “watchful waiting” as the initial management of an invasive cancer.
An eminent radiologist counterattacks
As much as I might have been disappointed in Dr. Schattner’s reaction, I understand it, at least as much as someone who has never had (and is incredibly unlikely ever to have) breast cancer can. I take care of women like her, and I am active with our local Komen group. So I think I get where Dr. Schattner’s coming from.
Unsurprisingly, though, it didn’t take long for a man who is known as a pit bull defending mammography against all studies that cast even an infinitesimal amount of doubt on it as a pure, unalloyed good for all women (over 40, at least) all the time, Dr. Daniel Kopans, to jump into the fray in his usual inimitable and entirely predictable fashion. We’ve met Dr. Kopans before. He is an eminent radiologist. Dr. Kopans is also prone to apocalyptic rhetoric about the consequences of any study that might decrease the rate of uptake of mammograms, basically portraying anyone who questions whether mammography is as effective as he thinks it is as wanting to kill women. His overall message is that overdiagnosis doesn’t exist and, even if it does, it isn’t a problem—except that it doesn’t exist. (I exaggerate, but not by much.) Unfortunately, his attitude towards anyone who suggests otherwise, especially if they publish a study, is a problem is to attack, attack, attack. I know. I’ve had e-mail exchanges with some on the receiving end of Kopan’s “bull in a china shop” tactics and have even myself encountered them. It wouldn’t surprise me if I encounter them again if he ever becomes aware of this post.
So it’s not surprising that Dr. Kopans was—shall we say?—less than thrilled with the latest NEJM paper by Welch et al. Personally, I would have been surprised if he hadn’t weighed in rapidly, and the title of his “rebuttal” is actually pretty mild for him: New NEJM paper offers rehash on “overdiagnosis.” As usual, Dr. Kopans ridicules the study and portrays Welch and his co-authors as not just incompetent, but biased.
Here’s an example of what I mean:
It is surprising that the New England Journal of Medicine allowed an author to publish an almost identical analysis to a paper previously published in 2012. The new article by Welch et al is little more than a rehash of the 2012 paper by Bleyer and Welch that falsely claimed massive overdiagnosis of breast cancer.
The current study uses a similarly faulty methodology to that earlier work in the analysis of the incidence of breast cancer and its relationship to mammography screening. In the 2012 paper, Welch “guessed” that the incidence of breast cancer, had screening not begun in the mid-1980s, would have increased by 0.25% per year.
Notice the use of scare quotes and the dismissive language. Note its focus on the 2012 study, rather than the present study. The problem is that Archie Bleyer has already written a detailed defense of his and Welch’s methodology. Contrary to Dr. Kopans’ seeming view that Bleyer and Welch were biased against mammography, in fact, Welch and Bleyer did analyses to give mammography every benefit of the doubt. I don’t want to get in the weeds too much, but basically, Welch and Bleyer did analyses that took into account the sorts of complaints Dr. Kopans would later make. Also, the analysis, while similar to that of the 2012 paper, is not “identical.” For one thing, it doesn’t consider lymph node status.
What irritates me about Kopans is how he seems to willfully misunderstand the arguments and data supporting the concern that overdiagnosis is a problem:
By extrapolating this “underlying” rate to 2008, the authors estimated what the incidence would have been in 2008 had there not been any screening. Since the actual incidence was much higher, they claimed that the difference between the actual and their “guesstimate” represented cancers that would have never been clinically apparent had there not been mammography screening.
They called these cases “overdiagnosed,” suggesting that the cancers would have regressed or disappeared had they not been found by breast screening. They went on to claim that there were 70,000 of these “fake” cancers in 2008 alone, despite the fact that no one has ever seen a mammographically detected invasive breast cancer “disappear” on its own.
This is an obvious straw man argument, as any fair reading of the work of Welch et al from 2012 or now would show. Dr. Kopans is fond of claiming that those who are concerned about overdiagnosis, such as Dr. Welch, are saying that overdiagnosed breast cancers would “melt away” if left alone, obvious inflammatory straw man language designed to make Welch look ridiculous. Overdiagnosis means nothing of the sort. Again, overdiagnosed cancers might fail to progress, or they might progress so slowly that they don’t endanger the health of a woman in her remaining lifetime (however long that might be), or they might regress. We don’t know what proportion fall into which category of behavior—or even which cancers are overdiagnosed.
No one other than Dr. Kopans and those who don’t believe that overdiagnosis is real calls overdiagnosed cancers “fake” cancers. The very fact that Dr. Kopans would use such a flagrantly incorrect term shows that he either does not understand the concept of overdiagnosis or that he denies it and the cancer biology behind it. Again, as I emphasized above, overdiagnosed cancers are real cancers, not “fake.” They simply have a biological behavior that we are not used to thinking about. Because we do not yet have the tools to tell which screen-diagnosed cancers will or won’t progress, we end up overtreating a significant number of cancers. I’m also not entirely sure that no one has ever seen a mammographically detected invasive cancer disappear on its own, but even if that is true it shouldn’t be surprising. These days, we treat them all! From an ethics standpoint, we have to. Until we have the tools to predict biological behavior, we have to assume every cancer detected by mammography could endanger the life of the woman, and it would be unethical to do otherwise.
Dr. Kopans doesn’t stop there, though:
The NEJM published this denigration of mammography screening despite the fact that the authors had no data on which women had mammograms and which cancers were found by mammography. I have never seen a scientifically based paper in which an intervention (mammography) is blamed for an outcome when there are no data on the intervention relative to the outcome, yet the prestigious NEJM published the nonscience faulting mammography based on a “guess.”
I’m sorry. I realize that Dr. Kopans is an incredibly eminent radiologist who works at Harvard, and so much more famous, awesome, and influential than a mere peon like me, but writing that paragraph with a straight face must have been difficult. At least, it should have been. The study is epidemiology. We know when widespread mammographic screening was introduced. We also know that, between 1980 and 1990, the percentage of women having had a mammogram in the last two years went from a very low level to 50% of the population. Dr. Welch even cites those data in the supplemental material! Add to that all the disparaging language (“denigration” of mammography) and characterizing Welch’s estimates as “guesses” when Welch explains in great detail why he made the choices he did for his estimates in the supplemental materials, complete with sensitivity analyses for the assumptions. It’s far easier and lazier for Dr. Kopans just to dismiss them as “guesses,” though. Welch also notes that observed incidence always reflects “observational intensity.” In other words, the harder you look for a disease, the more of it you will find. This is a principle not unique to breast cancer. It applies to most diseases:
There is another piece of evidence suggesting that the increase in invasive cancer incidence observed during the 1980s does not reflect a true underlying increase in clinically meaningful breast cancer. Breast cancer mortality among women age 40+ was stable from 1975-1993 at 70-74 per 100,000, before beginning its steady decline to 48 per 100,000 in 2012 (a decline we argue is primarily treatment mediated). Stable mortality spanning the period of a 30% increase in invasive breast cancer incidence further argues that the increased incidence instead reflects the increased observational intensity associated with screening.
Dr. Kopans seems to spend most of his time attacking Welch’s 2012 paper rehashing the same tired arguments refuted by Bleyer, frequently not being entirely clear whether he’s criticizing the 2012 paper or the 2016 paper. Be that as it may, what bothers me the most about Dr. Kopans is his refusal to treat the question of overdiagnosis as a scientific disagreement over the exact amounts and types of harms to balance with the benefits of mammography and to portray those with whom he disagrees as villains. I don’t say this lightly. He has a long history of doing just that dating back over many years, for example, he has characterized Dr. Welch in the past as “trying to get thousands of women killed with his scientifically unsupportable ideas” and accused the investigators of a study that found no mortality benefit due to mammographic screening (the Canadian National Breast Screening Study) of scientific misconduct and then denying that he did that. He even called me a hypocrite and such an egotist that I would never admit I am wrong.
While it’s true that I might now have a bit of an ego, it’s not true that I won’t admit when I’m wrong. Dr. Kopans has just thus far failed to convince me. Certainly painting your opponents in a scientific debate as deceptive monsters intent on killing women doesn’t help him make his case, but it’s something Dr. Kopans has been doing at least since the 1990s.
Overdiagnosis is real
Given the randomized controlled clinical trials that show a much larger reduction in breast cancer mortality due to screening mammography, why is it that more recent studies like this one show a much more modest effect of screening on breast cancer mortality and a troubling degree of overdiagnosis? Well, it’s frequently the case that “real world” effectiveness is less than what is found in clinical trials; so this observation should not come as a surprise, particularly given that screening programs for cancer can take decades to provide sufficient data to evaluate their “real world” effectiveness. It should also not be a surprise that breast cancer treatment has been getting better and that that might make mammography less useful than it was 30 years ago. It’s also very complicated, as Welch points out:
There is no perfectly precise method to assess the population effects of cancer screening. Screening mammography performed in an asymptomatic population that has an average risk of cancer can, at best, have only a small absolute effect on cancer-specific mortality because the vast majority of women are not destined to die from the target cancer. Because the mortality effect is necessarily delayed in time, the availability of improving cancer treatment over time further complicates the assessment of the contribution of screening. Inferences regarding overdiagnosis are equally imprecise since overdiagnosis cannot be measured directly.
I also note that I’m not claiming that there are not legitimate criticisms to be made about Dr. Welch’s paper. Oddly enough, Dr. Kopans almost ignored them. For instance, one can question the assumptions Welch et al made to fill in missing tumor size values for the early years of the SEER Database, when it wasn’t as complete to estimate size-specific incidence. The paper isn’t perfect. Because it’s based on data in the SEER Database, it is, like most epidemiological papers based on that database, rather messy. However much we can argue about the magnitude of the problem, I was unable to find sufficient problems with Welch’s methodology to seriously question his conclusion that overdiagnosis is real and a major problem with mammography. Neither was Joann G. Elmore, MD, MPH, after noting in an accompanying editorial that Welch et al “rely on data with extensive missing values, forcing them to make assumptions about underlying disease burden that cannot be verified, which is why they acknowledge that their estimates are imprecise.” I don’t think they’re imprecise enough to invalidate this paper, however.
More importantly, Dr. Elmore also provides an excellent money quote to think about whenever we discuss screening for breast cancer:
We are using archaic disease-classification systems with inadequate vetting and defective nosologic boundaries. Diagnostic thresholds for “abnormality” need to be revised because the middle and lower boundaries of these classification systems have expanded without a clear benefit to patients. Disease-classification systems are often developed by experts on the basis of a small number of ideal cases and are then adopted broadly into clinical practice — a system that is antithetical to the scientific process. The National Academies of Sciences, Engineering, and Medicine recently deemed improvement of the diagnostic process “a moral, professional, and public health imperative.” Rigorous analytic methods are required for the development of disease nosologies, and physicians need more sophisticated tools to improve diagnostic precision and accuracy. At the patient level, we need better methods of distinguishing biologically self-limited tumors from harmful tumors that progress.
Exactly. In cancer, I consider that last need to be the most critical of all. Mammography is a test that detects anatomic abnormalities to diagnose disease, but if there’s anything we’ve learned over the past couple of decades it’s that, when it comes to cancer, anatomy is not king. Biology is. We require biological markers that tell us which of these tumors detected by mammography are safe to keep an eye on through “watchful waiting” and which are dangerous. Until we have these tools (and, contrary to Dr. Schattner’s assertion, we do not as yet have these tools), overdiagnosis will remain a problem.
Here’s the thing. People will see what they want to see in this study. Those who believe screening saves lives will argue that the small benefit observed is worth the cost of overdiagnosis or will try to argue that Welch greatly overestimates how much overdiagnosis there is. Even so, contrary to Dr. Kopan’s disparaging dismissal of overdiagnosis as, in essence, a campaign against women to reduce access to lifesaving screening tests, there is a growing evidence supporting a broad consensus that overdiagnosis due to mammography is a significant problem to be overcome. Indeed, new suggested mammography guidelines that have been recommended in the last few years have come about because of a desire to decrease overdiagnosis and overtreatment while maintaining early detection of potentially dangerous tumors. In contrast, the mammography “nihilists,” as I like to call them, will point to this study as saying that screening mammography is useless.
Overdiagnosis is a real problem. We might argue about the magnitude of the problem, whether its frequency is nonexistent (as Dr. Kopan seems to argue), a few percent (as radiologists will frequently argue) or whether it is as high as 80%, as this study implies, but, contrary to the claims of prominent radiologists, it is a real phenomenon and a real problem. It confounds more than just mammographic screening programs; it confounds any screening program, because, as we’re discovering, preclinical disease in asymptomatic patients that either never progresses or progresses very slowly is far more common than we have previously suspected.
In the end, science can never really fully answer whether a woman should undergo mammography or whether mass screening programs are worthwhile, be they for breast cancer, prostate cancer, or other diseases. The reason is that no matter how much science is brought to bear, there will be no escaping the facts that the final decision will boil down to a value judgment informed by the science and that, because, contrary to what Dr. Kopans has suggested in the past, we can’t do a randomized clinical trial of mammography any more because there would not be clinical equipoise. In the US, we are very pro-screening, but that doesn’t necessarily mean that our care is better. In any case, when it comes to mammography, the value judgment to be made is simple to state but very hard to answer: Is the small decrease in a woman’s chance of dying of breast cancer worth the not-inconsiderable risk of overdiagnosis and subsequent harm from overtreatment? Many women will answer yes. Some will answer no. Different women will make different choices, and different people will have different opinions, depending on what they consider more important.