{kind=link}
![]() Note: The reason that I am posting today rather than my usual Monday slot is because the article I discuss here was embargoed until last night. Consequently, I asked Harriet if she would trade days with me this week, and she was kind enough to do so.
Note: The reason that I am posting today rather than my usual Monday slot is because the article I discuss here was embargoed until last night. Consequently, I asked Harriet if she would trade days with me this week, and she was kind enough to do so.
One thing that science relies on almost absolutely is transparency. Because one of the most important aspects of science is the testing of new results by other investigators to see if they hold up, the diligent recording of scientific results is critical, but even more important is the publication of results. Indeed, the most important peer review is not the peer review that occurs before publication. After all, that peer review usually consists of an editor and anywhere from one to four peer reviewers on average. Most articles that I have published were reviewed by two or three reviewers. No, the most important peer review is what occurs after a scientist’s results are published. Then, all interested scientists in the field who read the article can look for any weakness in methodology, data analysis, or interpretations. They can also attempt to replicate it, usually as a prelude to trying to build on it.
Arguably nowhere is this transparency quite as critical as in the world of clinical trials. The reason is that medications are approved on the basis of these trials; physicians choose treatments; and different medications become accepted as the standard of care. Physicians rely on these trials, as do regulatory bodies. Moreover, there is also the issue of publication bias. It is known that “positive” trials, trials in which the study medication or treatment is found to be either efficacious compared to a placebo or more efficacious than the older drug or treatment it is to replace, are more likely to be published. That is why, more and more, steps are being taken to assure that all clinical trial results are made publicly available. For example, federal law requires that all federally-funded clinical trials be registered at ClinicalTrials.gov at their inception, and peer-reviewed journals will not publish the results of a clinical trial if it hasn’t been registered there. Also, beginning September 27, 2008, the US Food and Drug Administration Amendments Act of 2007 (FDAAA) will require that clinical trials results be made publicly available on the Internet through an expanded “registry and results data bank,” described thusly. Under FDAAA, enrollment and outcomes data from trials of drugs, biologics, and devices (excluding phase I trials) must appear in an open repository associated with the trial’s registration, generally within a year of the trial’s completion, whether or not these results have been published. Although there are some practical issues over this law, for example determining how much information can be disseminated this way without constituting prior publication, which is normally a reason to disqualify a manuscript from publication.
Today, a rather telling study was published in PLoS Medicine. Undertaken by Ida Sim and colleagues at the University of California at San Francisco, the study, entitled Publication of clinical trials supporting successful new drug applications: A literature analysis (press release here), suggests a need for greater transparency. Sim and colleagues took a rather obvious tack and went to the literature itself to look at the evidence used to support FDA approval of new drugs to see how much of it is actually published. The results, even if they overestimate the effect reported, are disturbing. It turns out that more than half of the clinical trials used to support FDA approval of drugs remain unpublished more than five years after that approval. There are several disturbing implications that derive from this observation. More on that later. But first let’s look at the study’s methodology.
Briefly, Sims et al conducted a cohort study of clinical trials supporting new drug applications (NDAs) that were approved between 1998 and 2000. Drugs were identified by a search of the FDA website. They further looked at trials deemed “pivotal.” Pivotal trials are trials that demonstrate the efficacy and safety of a drug for its proposed indication. They are the trials that, according to the manufacturer and the FDA, provide the most useful information for deciding whether to approve the drug and for clinical decision-making. Thus, trials were divided into “pivotal” and “nonpivotal.” In essence, trials described in the summary documents for each drug approval and/or in the “clinical studies” section of the correspponding drug label were categorized as “pivotal.” Sims et al then systematically searched common databases of medical journals in which the results of such trials would be likely to be published, including PubMed, the Cochrane Library, and the Cumulative Index for Nursing and Allied Health Literature (CINAHL). Searches were performed on the drug’s generic name and “Publication Type: Clinical Trial,” and all English-language medical literature was searched. Trials used in the FDA review of a drug were then matched to publications based on a number of characteristics. Finally, for trials not located this way, additional searches were performed using just the drug’s generic name and a number of keywords designed to locate clinical trials that might have been missed in the original search strategy. The results were smmarized as follows (you can read the entire article yourself for the full details):
We identified 909 trials supporting 90 approved drugs in the FDA reviews, of which 43% (394/909) were published. Among the subset of trials described in the FDA-approved drug label and classified as ‘‘pivotal trials’’ for our analysis, 76% (257/340) were published. In multivariable logistic regression for all trials 5 y postapproval, likelihood of publication correlated with statistically significant results (odds ratio [OR] 3.03, 95% confidence interval [CI] 1.78–5.17); larger sample sizes (OR 1.33 per 2-fold increase in sample size, 95% CI 1.17–1.52); and pivotal status (OR 5.31, 95% CI 3.30–8.55). In multivariable logistic regression for only the pivotal trials 5 y postapproval, likelihood of publication correlated with statistically significant results (OR 2.96, 95% CI 1.24– 7.06) and larger sample sizes (OR 1.47 per 2-fold increase in sample size, 95% CI 1.15–1.88). Statistically significant results and larger sample sizes were also predictive of publication at 2 y postapproval and in multivariable Cox proportional models for all trials and the subset of pivotal trials.
A depressing additional observation was that the percentage of trials published in the peer-reviewed literature ranged from 0-100%, with a mean of 55%. That’s right; there were drugs that had 0% of the trials supporting their FDA approval published over five years later. Overall, this is what the results looked like:
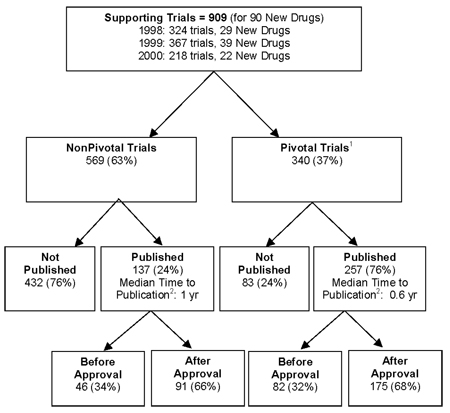
One thing that I found reassuring in the figure above is that there were in general approximately ten clinical trials for each new drug to be approved by the FDA. That is actually somewhat more than I would have expected, and it actually somewhat reassures me about our drug approval process. A lot of time, money, effort, and science go into approving a new drug. Of course, it is exatly alll that time, money, and effort that lead companies to expect a return on their investment, which is why they might be less likely to want to publish equivocal or negative studies. This survey isn’t perfect, but it does give a pretty good indications of the situation out there in terms of publication bias in favor of positive studies. If it is in error, it is most likely an error of underestimating how many clinical trials were published because of misclassification of some trials as being unpublished when they actually were published. However, the authors make a very good point about this potential problem:
However, we believe that for clinicians and policy makers, the most relevant publication rate is not the overall rate but the publication rate in journals that a typical clinician, consumer, or policy maker would have access to through a reasonable literature search. We believe our searches of PubMed, the Cochrane Library, and CINAHL reflect such a reasonable search. It would not be reasonable to expect a clinician, consumer, or policy maker to contact investigators or sponsors to determine a trial’s publication status.
Another potential weakness might be that five years wasn’t a long enough followup time. However, the authors found that nearly all publications occurred within three years after FDA approval. These limitations aside, this study is highly suggestive that in the early years after the approval of a drug there is a significant publication bias favoring clinical trials with positive results over those with negative results. Thus, initially the medical literature tends to contain publications that may exaggerate the advantages of new drugs over old or falsely suggest that new drugs are more efficacious and/or safer than old drugs, and this study estimates the approximate magnitude of that bias in the literature. This article in PLoS thus serves as a good estimate of the baseline for publication bias that can be used to determine the effect of the FDAAA.
Although on the surface, the dictates of the FDAAA might appear to be an unalloyed good, that may not entirely be the case. Indeed, Sims et al suggest paradoxical harm to transparency in reporting clinicial trials:
Paradoxically, however, this new law may increase rather than decrease publication bias. Might sponsors feel less compelled to publish equivocal trials because the basic results will already be in the public domain? Might the time pressure to submit manuscripts by 1 y postapproval focus sponsor efforts even more on submitting positive trials and trials of greatest interest to journals? Might the journals, if they accept manuscripts of trials with publicly posted results, change the criteria by which publication importance is judged, and how might this affect acceptance rates [28]? When more detailed protocol information must also be posted on ClinicalTrials.gov, to start no later than October 2010, the effect on publication practices is even harder to anticipate.
Indeed, three months ago, the PLoS editors, while generally strongly supporting the law, expressed similar concerns:
Under FDAAA, will the initial reporting instead become the sole province of those with the greatest financial or personal interest in a favorable result, without the benefit of dispassionate evaluation? Will the public find itself beset by press coverage of post-hoc subgroup analyses, overgeneralizations of results, or improper statistical treatments, slickly packaged as medical breakthroughs? Or will immediate and universal access via the Internet to an ever-increasing number of health-savvy readers provide a better level of scrutiny? (These savvy readers include experienced care providers, patient and professional organizations, consumer advocates, specialty bloggers, health reporters, and entire fields of researchers—not just the few selected to perform formal peer review of a given trial.) Given that trials results must now be released irrespective of “formal” publication in a journal, it surely makes sense to ensure that the public dataset for every trial contains sufficient information to permit objective evaluation of the trial’s findings for each prespecified study outcome.
In the best case, unfettered access by these parties would provide radical improvements over the current system, in which limited access to data hampers systematic review and abets disingenuous drug marketing. It’s not difficult to imagine a vigorous network of skilled evaluators serving as watchdogs over posted data that have been misrepresented or remain unpublished. Perhaps peer-reviewed journals will provide a forum for publishing independent analyses of such datasets. The appearance of such articles would mark a full circle affirming the contribution of formal peer review, but would also demonstrate the value of openly available results.
It would not be surprising if there were a “shake-out” period for this new law, in which there is some confusion and perhaps unintended effects. Indeed, I’d be surprised if there weren’t and would expect there to be consequences not forseen in either of the analysess quoted. How scientific data from clinical trials find their way to the peer-reviewed literature is complex and, yes, more than a little tradition-bound. It has only been relatively recently, with a series of controversies concerning the alleged suppression of safety risks of drugs such as rosiglitazone (Avandia), paroxetine (Paxil), and rofecoxib (Vioxx). Indeed, I wrote extensively about another form of corrupting the clinical trial evidence (i.e., seeding trials) about a month ago, a form of clinical trial corruption that I labeled at the time a “threat to science-based medicine.” In contrast, the publication bias revealed by Sims et al is a more insidious threat to science-based medicine in that it is a problem inherent in the system The FDAAA represents a necessary first step in correcting this this bias, but it will be impossible to estimate its effect without a baseline to compare to. By quantifying the publication bias inherent in the system and providing that baseline, Sims et al have done a service to science-based medicine.
REFERENCES:
1. Kirby Lee, Peter Bacchetti, Ida Sim, Mike Clarke (2008). Publication of Clinical Trials Supporting Successful New Drug Applications: A Literature Analysis PLoS Medicine, 5 (9) DOI: 10.1371/journal.pmed.0050191
2. PLoS Editors (2008). Next Stop, Don’t Block the Doors: Opening Up Access to Clinical Trials Results PLoS Medicine, 5 (7) DOI: 10.1371/journal.pmed.0050160