{kind=link}
[Editor’s note: Dr. Novella is unable to provide a post today, so in his stead we welcome back to the blog guest contributor Dr. Jim Coyne!]
The opioid crisis and growing awareness of the dangers of addiction to pain medication are prompting renewed calls for the use of pill placebos in place of active treatments, backed by familiar claims about the magical powers of the placebo.
Witness the press release for a recent study in the prestigious Nature Communications: “ Sugar pills relieve pain for chronic pain patients“.
Here are some excerpts:
“Their brain is already tuned to respond,” said senior study author A. Vania Apkarian, professor of physiology at Northwestern University Feinberg School of Medicine. “They have the appropriate psychology and biology that puts them in a cognitive state that as soon as you say, ‘this may make your pain better,’ their pain gets better.”
There’s no need to fool the patient, Apkarian said.
“You can tell them, ‘I’m giving you a drug that has no physiological effect but your brain will respond to it,'” he said. “You don’t need to hide it. There is a biology behind the placebo response.”
And:
The individuals whose pain decreased as a result of the sugar pill had a similar brain anatomy and psychological traits. The right side of their emotional brain was larger than the left, and they had a larger cortical sensory area than people who were not responsive to the placebo. The chronic pain placebo responders also were emotionally self-aware, sensitive to painful situations and mindful of their environment.
And:
Prescribing non-active drugs rather than active drugs. “It’s much better to give someone a non-active drug rather than an active drug and get the same result,” Apkarian said. “Most pharmacological treatments have long-term adverse effects or addictive properties. Placebo becomes as good an option for treatment as any drug we have on the market.”
None of these statements in the press release are tied to the actual findings of the study. Some of these statements are actually contradicted by the findings. But the press release was quickly echoed in the media around the world, with new exaggerations and distortions.
Funding
This study was funded by National Center for Complementary and Integrative Health grant AT007987 of the National Institutes of Health, the Canadian Institutes of Health Research, and Fonds de Recherche Santé Québec (a granting agency of one of Canada’s provinces).
Article processing costs for publishing in Nature Communications
Nature Communications only publishes articles open access. Article processing costs (APC) for the United States are $5,200. Given this high price, authors should be able to trust the journal to provide a rigorous peer review, correcting questionable publication and research practices in a way that would avoid the authors having to face post-publication criticism of their work in a blog post like this.
Criticizing the article and the review process that left its flaws intact, not just the authors
I am going to be hard on this particular article because it is an example of misleading claims about inert pill placebos that are being widely disseminated to lay and professional audiences. Because the article is published in a prestigious Nature Publishing Group journal and draws upon the mysteries of brain science, skeptics may be intimidated away from attempting to uncover obvious flaws. Would-be critics may feel discomfort with the notion that inert pill placebos could replace active treatments for chronic pain, but they may feel they lack the necessary expertise to criticize these kinds of arguments. However, I’m going to be pointing to some easily identified, basic problems that do not require a thorough background in neuroscience to expose. To paraphrase Bob Dylan, “You don’t need to be a neuroscientist to know…”
You will see what amazing discoveries can be made consulting a required CONSORT checklist for an article reporting a randomized trial or the trial registration. You will see how widespread publication bias in such studies is.
I will not be assuming that the authors consciously distorted the conduct and reporting of their study to “suit their own needs, corroborate their own predictions or otherwise make themselves look good.” This rampant methodological flexibility is highly prevalent in the biomedical literature, especially in neuroscience. A lot of honest researchers exploit this flexibility unintentionally. I believe that these authors can be considered cooks following instructions, rather than master chefs developing their own recipe. Regardless of their motivations, however, a journal that accepts $5,200 as an APC deserves some of the blame for not providing a more rigorous pre-publication peer review.
The Nature Communications article makes exaggerated claims about what a comparison between a pill-placebo condition and a no-treatment condition can possibly reveal. The paper is organized in a way that frustrates independent evaluation of its key claims. Tracking down the key details that are necessary for an independent appraisal is time consuming and difficult. The press release further inflates these claims and presents them with greater confidence than the results warrant.
Let’s take advantage of this open access article and official university press release to explore some wrongheaded notions about no-treatment comparisons and the magic of placebos.
Fortunately, we also have the benefit of open peer review. At the end of the paper, after the references, we find the “Peer Review File” [PDF]. In this file we find the original criticisms of the paper by the peer reviewers, and the authors’ rebuttals.
The abstract of the article
The placebo response is universally observed in clinical trials of pain treatments, yet the individual characteristics rendering a patient a ‘placebo responder’ remain unclear. Here, in chronic back pain patients, we demonstrate using MRI and fMRI that the response to placebo ‘analgesic’ pills depends on brain structure and function. Subcortical limbic volume asymmetry, sensorimotor cortical thickness, and functional coupling of prefrontal regions, anterior cingulate, and periaqueductal gray were predictive of response. These neural traits were present before exposure to the pill and most remained stable across treatment and washout periods. Further, psychological traits, including interoceptive awareness and openness, were also predictive of the magnitude of response. These results shed light on psychological, neuroanatomical, and neurophysiological principles determining placebo response in RCTs in chronic pain patients, and they suggest that the long-term beneficial effects of placebo, as observed in clinical settings, are partially predictable.
My initial reaction: this is a superficially persuasive, but grossly uninformative abstract. It leaves the reader in the dark about number of patients, how they were selected, and key elements of the design including the primary outcomes and analyses performed. I am suspicious of abstracts that defy conventional structure by declaring results in the second sentence. I have long campaigned for more informative abstracts that conform to CONSORT recommendations for abstracts. Unfortunately, I have not had much success, even with the journals on which I have been on the editorial board.
Nature Communications requires a completed CONSORT checklist to be uploaded with manuscripts when submitting a randomized controlled trial. Like most biomedical journals, Nature Communications does not enforce uploading the checklist for abstracts. The journal, its editor, and the reviewers share responsibility for the poor quality abstract published with this paper.
Looking for a trial registration
In probing a randomized trial, I highly recommend going immediately to PubMED and checking for trial registration as a first step. The trial registration should reveal basic details of the trial design, including designation of primary outcomes, and provide some reassurance that the authors did not exploit rampant methodological flexibility by selecting key findings and analyses, including designation of the primary outcome post-hoc (after peeking at their data). This common practice is known as hypothesizing after results are known or HARKing. But a good skeptic should be careful to check the date of trial registration to see if it was actually prospective, as many trial registrations are filed only after the authors have already peeked at their results.
CONSORT for abstracts requires that the abstract contain the trial registration number, which then gets automatically placed with the abstract in PubMED. The idea was to make it convenient to check the trial registration when accessing an article through PubMED. Unfortunately, I initially missed the registration number in this article because it was only mentioned in the dense text of the methods, which was near the end of the paper. When I found NCT02013427 I saw that this study is part of a larger clinical trial. The registration provides an excellent summary of what would be done in each of six patient visits, much more succinctly than what is in the actual article. The authors committed themselves to the primary outcome of current back pain intensity on a visual analog scale (0mm/no pain to 100mm/worst possible pain) at six weeks. We will see whether they stuck to this commitment.
Facilitating comparisons of primary outcomes initially declared to what appears in the published trail outcome paper is one of the most valuable functions of trial registration.
My preconceptions
My anticipation, based on previous experiences mainly probing claims about mindfulness based on MRI and fMRI research, is that the study would be grossly underpowered. There would be selective reporting of an improbable number of significant findings. Findings concerning functional and structural aspects of the brain related to placebo response would be consistent with past research, but just as unreliable and unlikely to generalize, except when the reporting is geared to confirming past findings. If I am proven correct in my suspicions, a gross confirmation bias should be evident in an article appearing in a literature already characterized by gross confirmation bias. But I was open to be proven wrong.
Digression 1: The scrambling of scientific communications
Just about the same time as the article and press release appeared, NeuroSkeptic posted a tweet that he had to quickly identify as satire in order to stem the confused commentary it was generating:
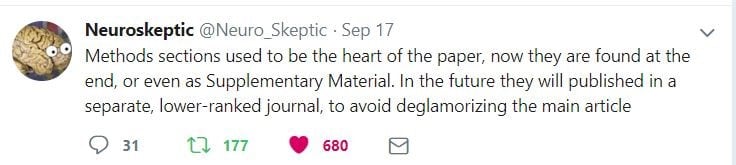
Unfortunately, this spoof description fit this article all too well. The six-paragraph introduction builds on the claims made in the uninformative abstract and ends with reports of some of the study’s results, integrated with a highly selective review of the literature. There is a masterful balancing of claims of great novelty to the study – that it included a no-treatment control – with claims that results were highly consistent with a robust predictability of the placebo response in the literature, in terms of psychological measures, brain structure, and function.
Casual readers will sit back and enjoy what seems to be a good story unfolding or stop reading altogether because they think they now know what was done in the study and what was found. Skeptics, however, will puzzle why we are having the results summarized without even the most minimal details of the methods that would allow independent evaluation of these claims. If skeptics know a bit about these kinds of studies, they will get suspicious that the story we are being told is highly edited, with selective reporting of what fits. Technically speaking, we could be in for an exploitation of investigator degrees of freedom, or possibly even a dead salmon.
Skeptics may note that a bold, but dubious claim has been slipped in:
Importantly, the effect size of placebo response is often equivalent to the active treatment studied and often even greater than that seen in conventional therapy. The duration of placebo responses has been shown to be comparable to those achieved with active treatments and the magnitude of placebo responses appear to be increasing in recent RCTs of neuropathic pain conducted in the US.
Active treatments that cannot be shown superior to placebo are not approved. A lot of promising treatments do not pass this initial test. That is why we have blinded, placebo-controlled randomized trials – to eliminate treatments that are ineffective.
Skeptics familiar with these kinds of studies will recognize that the authors have thoroughly confused placebo response with placebo effect (size). Placebo response refers to the within-condition: differences between baseline and follow up for a particular measure for patients assigned to pill-placebo. Such simple differences are unlikely to represent a placebo effect size. The placebo response incorporates the regression to the mean of pain scores due to patients having entered a trial at a time of heightened pain. These patients were required to stop taking any pain medication to participate in the study. However, placebo response also incorporates lots of nonspecific effects like the positive expectations associated with enrolling in a study, or the ritual of being prescribed and taking a pill in a particular context, namely, a medical setting with supportive personnel committed to getting the patient improved.
A no-treatment control does not provide such unambiguous information. Patients’ expectations of getting something in return for being in a trial are being violated by assignment to a no-treatment control group. Nothing is done for them, and they have assumed the burden of a lot of measurements in return visits. Any baseline-follow up differences on a pain measure cannot be assumed to be the natural history of what would have occurred in the absence of the patients enrolling in the study. There could well be a nocebo effect in play– patients assigned to no-treatment may be registering disappointment and distress that they have been denied extra attention and support and the healing ritual they anticipated from participation in a study.
I am a clinical health psychologist, as well as a skeptic. I expect to see that a placebo response explained in terms of brain function will underestimate the effects of the social environment and the patients’ past experience with a particular placebo. For instance, advertisements on TV about a powerful purple pill or patients’ own experience with purple pills will predispose them to have a larger response to a purple pill. Individual and group level placebo responses are quite variable and depended on the conditions under which they are observed.
With the end of a brief introduction, readers should next expect a description of methods that will allow independent evaluation of the results claimed by the authors. However, this article immediately launched into the results section, without even a specification of the range of variables from which reported results were selected. The article then proceeds to an interpretation and discussion of results. Finally, the methods are presented in a very dense fashion. I doubt many readers were motivated to delve in depth.
The CONSORT flowchart
When probing a randomized trial, I immediately go to the required CONSORT study flow chart, which often offers surprises as to the numbers of patients progressing from screening for suitability to randomization to retention across follow-up assessments. For this study, I had to go to the supplementary materials to get this:
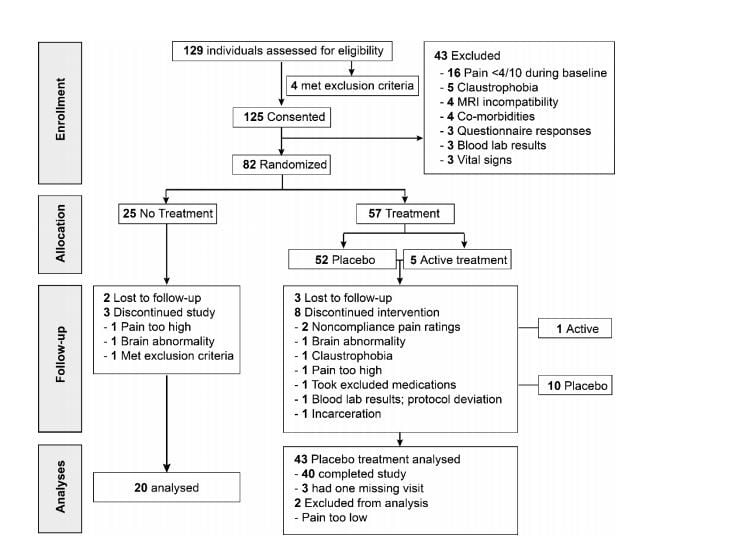

What I learned from the flowchart
The results reported in the Nature Communications paper were not the gold standard intent-to-treat analyses accounting for all of the patients randomized. Loss from each step down the flowchart to the next are unlikely to be random, which is a precondition for imputing variables to them. The small overall sample size does not allow testing for whether loss to follow-up is random.
Any comparison involving the no-treatment control group will suffer from it only having 20 patients available for analyses. Statistical power for a two-group study is tied to the number of patients in the smallest group.
Any comparisons involving this control group will not be adequately powered to detect even moderate associations, even when they are truly present. Furthermore, any significant differences that are found will have to be large in order to pass the higher threshold required for statistical significance with such a small sample.
If statistically significant differences are selectively reported, they are likely to be inflated and false positives. Furthermore, authors often rely on differences not being significant for making substantive interpretations or comparisons to the existing literature (i.e., “We fail to replicate past findings that…”). This will be a mistake because many differences are only nonsignificant because the number of patients is too small to detect an association, if it is actually there. However, we have to avoid the assumption that increasing sample size would guarantee that the apparent association would become significant, because we do not know if it is due to chance.
A lot of the analyses most crucial to the authors’ arguments will depend on analyses of the 40 patients assigned to the pill-placebo condition. However, the number of patients is insufficient to reliably detect moderate correlations between self-report scores and measures of brain function. Furthermore, a lot of the most crucial analyses depend on distinguishing between responders and nonresponders. That involves dividing the 40 patients into two groups of 20 each. There are a number of problems here. The responder/nonresponder distinction depends on a subjective self-report measure. The particular cutoff distinguishing responders from nonresponders is arbitrary and depends on the particular self-report measure being used. As we will see, the authors switched from their initial commitment when registering the trial – the 6 month visual analogue scale results.
Comparing two groups of 20 brains requires some statistical control for natural interindividual differences in brain anatomy and intra-individual differences in the stability of measurements. One or two unusually-sized brains or unexplained interindividual differences across assessments could push results above or below the threshold for statistical significance.
As you can see, we can learn so much from a CONSORT flowchart and that is why journals generally required the flowchart be prominently displayed. But few people look at the numbers in the boxes.
Focusing only on what the numbers in the CONSORT flowchart boxes reveal, I confirmed my suspicion that the results of this study are too small to produce meaningful statistically significant findings that will be robust and likely to be replicated in a larger study (à la John Ioannidis). Findings from past studies are unlikely to be replicated in this study if statistical significance is the criterion, again because the sample is too small. Focusing on responders vs non responders is likely to compound the problems because it involves splitting an already small simple into two even smaller halves. As we will see, measurement of brain structure and function have a lot of noise and so larger samples are needed to refine and correct these measurements. Specific differences between the brains of responders vs nonresponders are likely to be unreliable and won’t replicate in new samples. Appearances to the contrary are likely to be due to selective reporting, searches for confirmatory findings, and exploitation of rampant methodological flexibility in this and other studies.
Other annoying features of the study that may have influenced reporting
We have no idea what specific descriptions of the study were used to recruit patients. Details would be important to understand why patients were willing to enroll in a study that required them to get off medication for chronic back problems and the extent to which they might have been disappointed when they got assigned to a no treatment group. We do not know what expectations the patients had for the two periods in which they were no longer taking the pill-placebo. Details would have been useful to understand the psychosocial influences on their pain ratings during those periods.
Key findings
Primary outcome
The authors downgraded the primary outcome declared in the trial registration – back pain intensity on a visual analog scale at six weeks – to a secondary outcome. For their new primary outcome:
Throughout the duration of the trial, participants used a visual analogue scale, displayed on a smartphone app (Supplementary Figure 2), to rate back pain intensity two times per day in their natural environment. These ecological momentary assessments (EMAs) represented the primary pain measurement of this study and were used to determine placebo response.
The authors were thus capitalizing on one of the novel methodological features of their study. However, this means that the results are not readily compared to existing studies, which use a numeric rating scale completed during treatment visits. Furthermore, the authors did some tweaking:
On average, responders showed a diminution in back pain intensity that stabilized to a constant value of about 20% analgesia for both treatment and washout periods (T1, T2, and W1, W2; Fig. 1d). Because some patients responded more strongly to one treatment period over the other, we calculated the magnitude of response as the highest %analgesia between the two treatment periods.
Maybe this is the reason for switched outcomes:
However, MPQ sensory and affective scales and PainDetect poorly correlated with our primary pain outcome (Supplementary Figure 3), did not differentiate between treatment cohorts, and groupings defined by the pain app showed improvement of symptoms in all groups.
It looks like a positive outcome was achieved with a sleight of hand. All other analyses depend on accepting this switch. Otherwise, the authors would not have had a placebo response to explain and a more difficult time making much fuss about responder/nonresponder differences.
Predicting placebo response from personality
We are told:
We sought to identify psychological parameters predisposing CBP patients to the placebo pill response from a battery of 15 questionnaires with 38 subscales.
That is almost as many variables to consider as there are participants assigned to the placebo condition (n= 40) and available for analyses. The authors imply that their focus on interoceptive awareness and openness as predictor variables was a priori and not made after peeking at the data. However, this choice ignores a literature in which these variables do not figure prominently in predicting self-reported pain data. Other variables are much stronger candidates. The authors then puzzle in their discussion that they did not replicate past studies of significant predictors, but they can expect to with so few. The threshold required for statistical significance would mean that any significant result had to be stronger than what appears in the literature for studies done with adequate sample sizes.
My conclusion: There are no significant predictors of responder/nonresponder from personality variables, once appropriate corrections for multiple comparisons are made for the numerous predictors that were examined. The authors acknowledge this at one point in the article, but then claim significant predictors in the abstract and throughout the rest of the paper. Recall the claims in the press release quoted at the beginning of this blog.
But the outcome variable used to define the responder/nonresponder divide was switched and the cells being compared (n= 20) were too small to produce robust, replicable predictors.
Digression 2: The untrustworthiness of usual sized studies of pain and the brain
The average correlation between a subjective self-report psychological measure and a biological variable across a large literature is probably ~.20, so we would need ~200 research participants for an adequately-powered study. Yet most studies of self-reported pain versus brain structure and function have less than 40 participants. Why, then, are there so many positive findings? There is reason to believe that authors preserve the appearance of consistency of findings across studies with:
- Considerable methodological and statistical flexibility in selecting from a wide range of possible measures
- Strategies for preparing findings for analyses including decisions about how to clean the data and control for large differences between individuals in size of brains and large differences across observations
- The choice of which complex multivariate model they use to analyze their data, and
- Selective reporting.
Readers’ confidence in findings is cultivated by beginning with selective attention to the existing literature in the justification for examining particular variables, and then selectively citing studies that fit whatever was found.
A graph from the paper “A Systematic review and meta-analysis of the brain structure associated with meditation” reveals some of the problem in a much larger literature.Technical note It is a scatter plot or funnel plot mapping the sample size against effect sizes found in the available literature. As can seen, there is a strong association between a study having a larger sample size and a smaller effect being obtained. That would not happen without a publication bias. The authors of the systematic review and meta analysis note:
Very large mean effect sizes (Cohen’s d > 1.0) were found exclusively in studies with relatively small sample sizes (n < 40). This could be because only small-n studies with large effects (and a higher chance of achieving significance) have been published, whereas many or all of the small-n studies with smaller effects are missing because they could not be published (a classic case of publication bias).
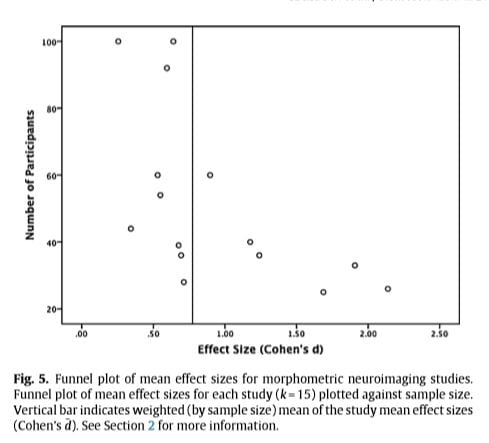
It would be good to return to the excerpts from the press release and abstract that were presented at the start of this blog. If you are shocked by what I have shown, please note that I consider it normative for this literature; nothing extraordinary except that so much was made of a the inclusion of a no-treatment control. Hopefully, the next time you encounter a press release or article arguing for the power of a placebo based on a no-treatment comparison/control group you will not have to put so much effort into scrutinizing the claims.
Note that in the present study of the brain and placebo response, the trial registration indicates that relating placebo response to measures of brain structure and function was one of the purposes of the study, but the registration did not specify specific hypotheses or variables to be examined – possibly making this an example of a Texas sharpshooter in action.
Brain volume and predisposition to placebo pill response
Rather than summarizing a dense, technical text, I will highlight some instances of the authors encountering null findings and then searching for statistical significance among additional findings.
The volumes of the NAc, amygdala, and hippocampus were first examined because they represent risk factors for developing pathological emotional state, chronic pain, and placebo response in healthy individual. Comparing subcortical volumes between PTxResp and PTxNonR [placebo responders versus nonresponders] was not informative. Given the recent evidence that subcortical volume asymmetry can provide a brain signature for psychopathologies, we followed-up examining inter-hemispheric laterality of the combined volume of these three structures. [Italics and hyperlinks added, citation numbers removed – Ed.]
In this area of research, it is now generally acknowledged that there are considerable differences between individuals in the overall size of their brains and that somehow these differences have to be taken into account. A technical discussion of these issues is beyond the scope of the current blog post, but I can refer interested readers to this excellent source concerning just how important these differences are and how unresolved they are.
Furthermore, the use of statistical controls in comparisons between such small groups (n=20) is particularly hazardous and are likely to produce a more biased estimate of effects than if statistical controls are not attempted.
fMRI measures of brain function
There are a large number of variables that could be measured, and the ones which will be considered are designated Regions of Interest (ROIs).
The brain was divided into 264 spherical ROIs (5-mm radius) located at coordinates showing reliable activity across a set of tasks and from the center of gravity of cortical patches constructed from resting state functional connectivity (Supplementary Figure 9a). Because subcortical limbic structures are believed to play a role in placebo response, 5-mm radius ROIs were manually added in bilateral amygdala, anterior hippocampus, posterior hippocampus, and NAc (Supplementary Figure 9b). Linear Pearson correlations were performed on time courses extracted and averaged within each brain parcel. Given a collection of 272 parcels, time courses are extracted to calculate a 272 × 272 correlation matrix.
This large range is narrowed by reference to what has been found in past studies, but reviewers pointed out that the past studies were from often very different populations. The authors note that their results do not fit with what is obtained with normal populations administered painful stimuli in the laboratory.
I recommend that interested readers consult the peer reviews of this article and the authors’ detailed responses, especially Reviewers 1, 3, and 4.
Takeaway tools for skeptics
The next time you encounter claims that the power of pill placebos for pain, backed to by a randomized trial measuring brain activity with fMRI, published in a prestigious journal, you may feel intimidated.
Don’t assume that because the paper is in prestigious journal that rigorous peer review ensured that the claims are based on best research and publication practices.
Check the abstract.
Be skeptical if the abstract does not provide basic details about the experimental design including how many patients were included and what primary outcome was specified.
Be skeptical if a trial registration number is not prominently displayed. Actually, check to see that the date of the registration is prior to the beginning of the study.
Be aware of how much information is available in a CONSORT flowchart. Check the flow of patients and be prepared for revelations that contradict and undermine the claims being made in the paper.
Warning signs of nonsense:
- A no-treatment comparison/control group, especially if the authors express confidence in the meaning of any differences between patients who were assigned to getting a pill versus those who got nothing.
- A placebo response being confused with a placebo effect and either placebo response or effect being considered fixed and generalizable across patients and social contexts.
Keep in mind that researchers can produce amazing but dubious evidence by taking advantage of rampant flexibility in methodological procedures, choice of variables to report, how the data is prepared for analysis, which of many analytic techniques are applied, and how they report and interpret results.
The seeming consistency of clinical neuroscience depends on shared biases in how to interpret studies too small to produced robust results and what findings of past studies are cited to explain or predict findings of a particular study after they are already known.
Ultimately, the gold standard in a study of pain response is a subjective self-report, which is vulnerable to all kinds of situational factors and just plain noise.
Functional and structural measures of the brain might be used to explain subjective self-reports of pain, but they are not a substitute. Ultimately, the meaning of brain measurements in pain research depend on unreliable subjective self-reports for their validity. Few pain patients seek treatment for their objective brain measurements; what they want is relief from the subjective experience of pain.
- Technical note: Prior to constructing the scatter plot above, Fox et al. (2014) attempted to correct for suspected bias in this literature by using two different deflation coefficients. The effect sizes displayed in the plot are reduced and ~42% of the effect sizes reported in the original articles. A very similar scatter plot for functional neuroimaging studies of meditation (Fox et al. (2016). Taken together, this suggests a pervasive bias in brain studies of meditation, backing the argument that what was done by the authors of the present study of the brain and pill-placebo response in pain is nothing unusual and conformed to normative practices. See Section 2.5.3 Other caveats regarding effect sizes in neuroimaging in Fox et al. (2014) for further discussion of problems in analyzing mean effect sizes in neuroimaging studies (back to text).